L’inverse pour moi, j’inclue par défaut tout et j’exclue au cas par cas ou au niveau d’un domaine ou de patterns.
Donc à chaque fois que tu fais une modif, il faut penser à vérifier si ça remplit pas la base pour rien… Chacun gère comme il a envie, mais perso j’ai pas besoin de surveiller (le cas de @pctetra ne m’arrivera surement pas aussi facilement) et je ne suis pas fan de stocker plein de données pour ne rien faire
Oui et non en excluant des domaines, en normalisant les noms de tes devices et en utilisant des patterns, tu n’as rien à faire 99% du temps.
Il y a que des le cas d’un nouveau type de devices que c’est nécessaire (du coup comme pour toi en fait).
Le lixee (au moins via z2m), envoie des données très régulier (tous les 12secondes chez moi) x nombre l’entité* nb jour d’historique = ça fait exploser la taille de la bdd de HA, …
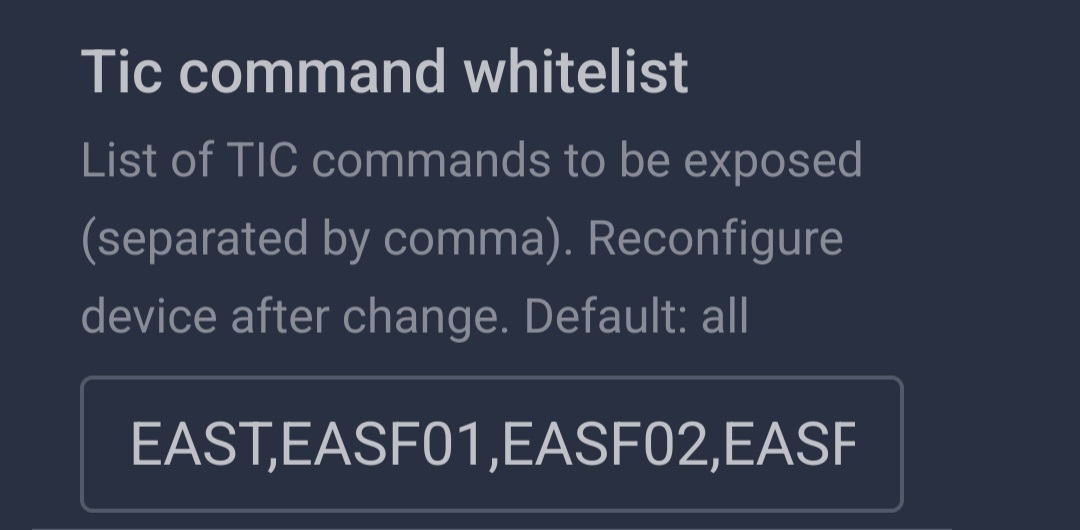
Tu peux, et c’est fortement recommandé de mettre la whitelist qui expose que les attributs du lixee utile dans HA.
Puis, tu peux désactiver l’historique sur des sensors dont tu veux des infos mais pas forcément avoir d’historique
effectivement j’ai refait mon recorde.yaml comme tu l’as indiqué, quand je compare état statistiques de ce qui n’est pas enregistré dans outil développement, je suis arrivé au même résultat avec 5 lignes dans le recorder.yaml par rapport au nombre de exclude que j’avais.
a suivre
Avec la méthode préconisée ci-dessus les données sont automatiquement exclues de l’enregistrement
Rien vu la dessus, tu peux préciser ?
Le retour de Pulpy-Luke
oui j’avais vu ça, effectivement. merci
je suis d’accord, et il a deux qualités pour moi, c’est un ancien jeedom et il fait partie des 2 premiers qui m’ont aidé quand j’ai commencé à migrer sur HA ![]()
1 « J'aime »
Je ne suis pas infaillible non plus, hein ![]()
Et je découvre encore des trucs sur HA en lisant vos messages
Ces paramètres sont ceux du mode standard, je suis resté en mode historique, le mode standard n’a pas d’intérêt pour mon usage.
Du coup j’ai moins de données qui remontent, qu’avec le mode standard, pratiquement que de l’utile à 2 ou 3 exceptions prêt
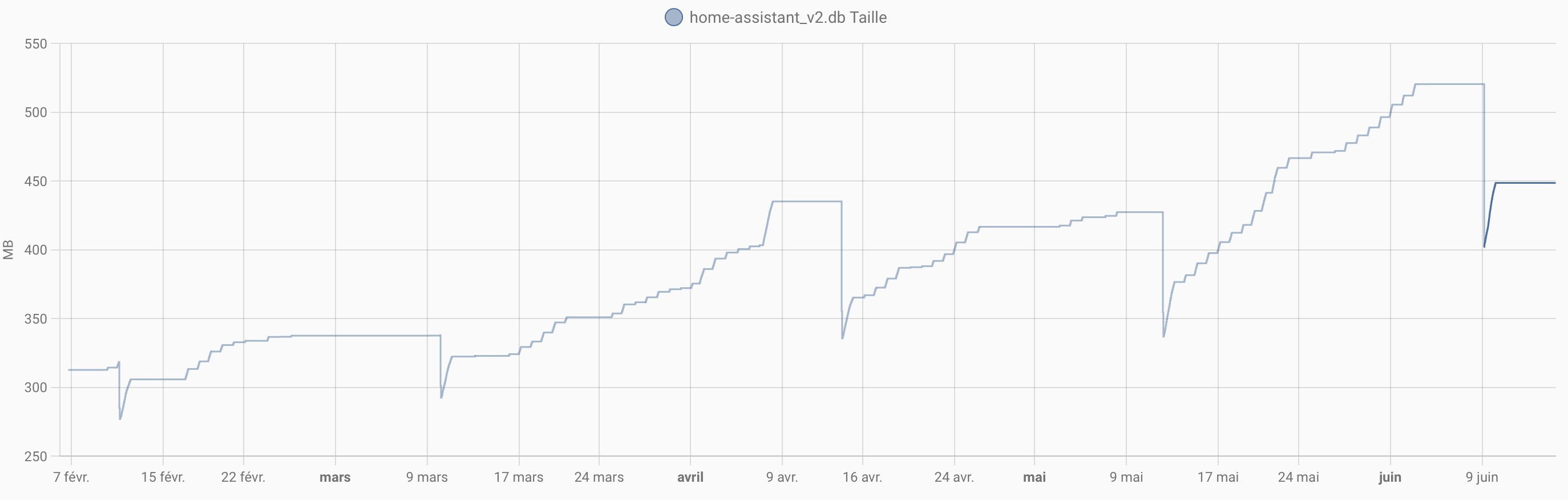
Ce sujet de taille de base de donnée m’intéresse. J’ai démarré avec HA courant décembre et vise à mettre en oeuvre d’aussi bonnes pratiques que possible. Quelle taille de BDD est raisonnable ou a quel seuil faut il se méfier ? Pour le moment, l’intégration taille de fichier, en service depuis 8 jours, me donne une valeur autour de 310 MB.
Bonsoir
Pour avoir beaucoup lu sur le sujet ça dépend de beaucoup de paramètres, du type d’installation, en VM ou pas, du nombre d’équipements qui remonte dés données…
300mo c’est très raisonnable
J’ajouterai que vu les problèmes que je viens d’avoir, la stabilité de la taille est gage de bonne santé même si elle peut monter un peu mais progressivement.
Moi quand ça c’est dégradé ça a été très vite, de 500Mo à 5go en quelques heures
1 « J'aime »
Ok. Je garde ce sujet « recorder » sous le coude et je vais surveiller ma bdd sur quelques semaines/ mois avant de bouger.
Bonjour, n’hésites pas à marquer ce problème comme résolu afin de garder le forum à jour.
je suppose que ça s’adresse à moi qui ait créé le topic
oui c’est prévu je ferais d’ici la fin de semaine s’il se confirme que c’est réglé, pour l’instant tout va bien.
mais ![]()
la dernière fois ça c’est dégradé au bout de deux jours
Oui, le volume de la bdd est très variable et elle est surtout lié au nombre de capteur remonter * la fréquence de réception.
il y a 2ans (avant mon emporia vue2 & le Lixee principalement), j’arrivai à avoir que 50Mo de bdd bien optimisé.
Mais maintenant, je suis a 1Go et c’est pourtant super optimiser
- mais l’emporia vue 2 me remonte 40 capteurs * tous les 5 secondes, que je garde 7jours ( soit environ 5 millions de valeurs )
- et le lixee me remonte 14 capteurs * tous les 12 secondes, que je garde 7jours ( ~ 700 000 valeurs )
Pensez à ajouter des scripts pour purger vos données avant d’attendre que le recorder le fasse.
Dans mon cas, je demande au recorder de les conserver 30j, j’ai un script qui purge certaines données au bout de 7 jours et un autre toutes les 24h.
Cela me permet d’avoir un historique en fonction dès besoins.
En gros, cela m’intéresse peu de connaître le statut de mes capteurs d’ouverture plus de 24h, cela m’intéresse pas trop d’avoir une infos précise sur le cpu utilisé par mes containers docker plus de 7j, par contre j’ai besoin d’un historique précis sur les températures sur 30j (puis les statistiques à long terme prennent le relais).
De plus la taille du fichier ne dit pas tout, car sans repack, l’espace libre n’est pas libéré.
Bonjour.
Je reviens sur le sujet.
A ce jour, Je n’ai pas fait de config du recorder. Ma BDD fait 448 MB et est purgée de façon automatique. Néanmoins, l’augmentation est constante depuis février.
Si j’ai bien compris :
Toute entitée avec un State_Class measurement, total ou total_increasing est conservée ad vitam
Tout le reste n’est conservé que 10 jours selon les paramètres par défaut du recorder.
L’idée serait donc de mettre en include dans le recorder, que les sensor avec state_class qui m’intéressent réellement (index teleinfo via teleinfo2mqtt, prod solaire quotidienne, 2-3 autres choses liées à l’énergie, certaines températures). Ainsi, le superflus dégagera aussi (l’historique de qualité de signal de mon micro onduleur solaire ou la tension, je m’en cogne par exemple). Je m’imagine mal avoir besoin de conserver autre chose.