Merci, ça marche effectivement beaucoup mieux comme ça !
1 « J'aime »
2 petites questions:
-
Quel modèle pour Vosk ? Pour l’instant, j’ai pris celui-ci: vosk-model-fr-0.22.zip mais il y a peut-être mieux ?
-
Piper me hurle assez souvent qu’il n’a pas compris, il y aurait un moyen quelque part de baisser le volume ? Mon micro/HP Anker S330 est connecté sur un NUC avec Proxmox.
Salut @FillR2 ,
j’ai vu que tu parlais de modèle pour Vosk, mais ca sert a quoi ?
Le modèle, c’est le coeur du système IA, c’est ce qui a été entrainé à faire une tâche à partir de données existantes.
Dans le cas de Vosk, le modèle, c’est ce qui a été entrainé pour faire la détection de voix la plus fiable possible, il y a des modèles entraînés à faire de la reconnaissance en anglais, en espagnol, en français.
Et ici, plusieurs modèles sont proposés:
La question est de savoir lequel est le plus fiable entre:
| French | ||||
|---|---|---|---|---|
| vosk-model-small-fr-0.22 | 41M | 23.95 (cv test) 19.30 (mtedx) 27.25 (podcast) | Lightweight wideband model for Android/iOS and RPi | Apache 2.0 |
| vosk-model-fr-0.22 | 1.4G | 14.72 (cv test) 11.64 (mls) 13.10 (mtedx) 21.61 (podcast) 13.22 (voxpopuli) | Big accurate model for servers | Apache 2.0 |
| French Other | ||||
| vosk-model-small-fr-pguyot-0.3 | 39M | 37.04 (cv test) 28.72 (mtedx) 37.46 (podcast) | Lightweight wideband model for Android and RPi trained by Paul Guyot | CC-BY-NC-SA 4.0 |
| vosk-model-fr-0.6-linto-2.2.0 | 1.5G | 16.19 (cv test) 16.44 (mtedx) 23.77 (podcast) 0.4xRT | Model from LINTO project | AGPL |
Le modèle doit être dézippé ici:
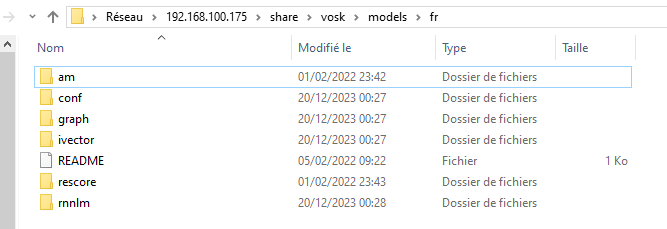
Quand tu lit ca:
Small model typically is around 50Mb in size and requires about 300Mb of memory in runtime. Big models are for the high-accuracy transcription on the server. Big models require up to 16Gb in memory since they apply advanced AI algorithms.
Pour mon cas sur RPI, faut le petit modèle a 40-50mo , qui mange 300MB de RAM.
A mon avis, pas besoin de changer le modèle par défaut.
Je n’ai aucune erreur de reconnaissance avec ce modèle
Plus le modèle est large, plus le temps de traitement est long.
2 « J'aime »
Temps mieux, ca m’évitera d’essayer et de perdre du temps ![]()
1 « J'aime »
J’ai utiliser celui-ci
vosk-model-fr-0.6-linto-2.2.0 1.5G 16.19 (cv test) 16.44 (mtedx) 23.77 (podcast) 0.4xRT Model from LINTO project
pas de problèmes particulier avec.
D’après la doc, faut un bonne machine ( pour un rpi4 faut oublier je pense ):
Citation
Big models require up to 16Gb in memory since they apply advanced AI algorithms.
Bonjour à tous.
Alors j’ai installé aujourd’hui la suite Assist. Comme mon HA est sur un Raspberry Pi 4 et qu’il y restera parce que c’est idéal, et que de toutes façons ça l’aurait pas fait, j’ai essayé sur un Raspberry Pi 5 où il n’y avait que RaspOS. J’ai installé ça dans des conteneurs docker, les tutos sont faciles. Aucun problème pour installer le serveur Wyoming et les intégrations dans HA. Et ça « marche », c’est à dire que quand je parle à mon appli HA surr mon téléphone, elle transmet ça à Whisper et puis tente d’interpréter le texte obtenu.
Ma conclusion est que malgré ses défauts je suis pas près de ranger mon Google Assistant.
Pour un phrase simple comme « allume la prise onze » (il y a un appareil « Prise 11 »), le truc mouline 10-15s, puis ne comprend rien. Je dois m’y reprendre à 10 fois sur différents tons pour avoir cette phrase verbalisée.
Si je regarde ce que fait le Pi 5 pendant que HA attend, je vois que python3 tourne à fond la caisse (sur tous les cœurs) pendant le traitement de la parole. Hein, du traitement du signal vocal (IA ou pas) en python ??? Normal que ça rame.
Ensuite la compréhension par HA est ras les pâquerettes. Il FAUT qu’il y ait une entité « prise 11 » pour qu’il comprenne. S’il y a un appareil de type switch appelé « Prise 11 », il ne trouve pas, même si l’entité est « Prise 11 commutateur »…
Mon impression est que les vidéos You Tube sont des « démos » avec la phrase pré-programmée qui lance une automation pour chaque « test », avec Whisper tournant sur le dernier Intel ou Ryzen à x GHz.
C’est juste mon avis.
Installe Vosk a la place de whisper, ça va te changer la vie, même avec un gros modèle : GitHub - rhasspy/hassio-addons: Add-ons for Home Assistant's Hass.IO
1 « J'aime »
Bonjour,
regarde ma démo sur un RPI4 avec un atom echo. J’ai utiliser Vosk et Snowboy ( je suis passer a porcupine ) .
Ton avis est pas bon, j’ai pas le dernier intel ou ryzen ![]()
j’ai rien préprogrammer sur la phrase, c’est une commande par défaut et le nom de ma pièce.

Bonjour
Voici ma configuration actuelle
## System Information
version | core-2024.2.0
-- | --
installation_type | Home Assistant OS
dev | false
hassio | true
docker | true
user | root
virtualenv | false
python_version | 3.12.1
os_name | Linux
os_version | 6.1.74-haos
arch | x86_64
timezone | Europe/Paris
config_dir | /config
<details><summary>Home Assistant Community Store</summary>
GitHub API | ok
-- | --
GitHub Content | ok
GitHub Web | ok
GitHub API Calls Remaining | 5000
Installed Version | 1.34.0
Stage | running
Available Repositories | 1391
Downloaded Repositories | 11
</details>
<details><summary>Home Assistant Cloud</summary>
logged_in | false
-- | --
can_reach_cert_server | ok
can_reach_cloud_auth | ok
can_reach_cloud | ok
</details>
<details><summary>Home Assistant Supervisor</summary>
host_os | Home Assistant OS 11.5
-- | --
update_channel | stable
supervisor_version | supervisor-2024.01.1
agent_version | 1.6.0
docker_version | 24.0.7
disk_total | 30.8 GB
disk_used | 6.5 GB
healthy | true
supported | true
board | ova
supervisor_api | ok
version_api | ok
installed_addons | Terminal & SSH (9.9.0), Studio Code Server (5.15.0)
</details>
<details><summary>Dashboards</summary>
dashboards | 1
-- | --
resources | 8
views | 11
mode | storage
</details>
<details><summary>Recorder</summary>
oldest_recorder_run | 7 février 2024 à 09:37
-- | --
current_recorder_run | 16 février 2024 à 15:46
estimated_db_size | 45.50 MiB
database_engine | sqlite
database_version | 3.44.2
</details>
Tous ca installé sur un Mac Mini (Fin 2014) 3 GHZ Core i7 - Memoire 8 GO 1600 MHz DDR3 + VirtualBox 6.1
Avec cette configuration est-ce qu’il est possible actuellement de pouvoir exécuter des commande vocal comme Ok google ? Mon objectif est de pouvoir commander ma domotique KNX à la voix
sans passer par Google
Mon ressenti pour l’instant :
Ça fonctionne, et c’est plutôt très réactif (en utilisant les bons modèles) .
Par contre, c’est débile, si tu ne dis pas la phrase pile poil comme il faut, il ne va pas comprendre.
La vraie différence, c’est qu’il n’y a pas d’IA derrière, donc ça transcrit littéralement ce que ça entend, et ça regarde si ça marche un des patterns connus.
De mon point de vue : pas utilisable en prod, je ne vais jamais réussir à éduquer femme et enfant à la rigueur nécessaire pour le faire fonctionner.
=> je conserve Alexa pour l’instant, mais les choses bougent vite, j’ai bon espoir
Hello tout le monde,
Petite question, je suis un peu perdu, j’essaie de faire fonctionner vosk avec Docker vu que j’ai tout qui est dockérisé sur ma machine ( je n’utilise pas HASS IO, j’ai pas de addon directement dans HA mais juste tous mes containers a coté que je manage avec docker-compose / portainer.
Mais du coup je voulais tester ‹ vosk › au lieu de ‹ whisper › qui traine un peu la patte niveau rapidité. Cependant je ne comprends pas comment démarrer le truc.
j’ai ca actuellement ( je ne suis même pas sur pour le port et donc comment l’ajouter apres a HA avec ‹ Wyoming Protocol › si j’ai pas le bon port coté vosk :
vosk:
container_name: vosk
image: rhasspy/wyoming-vosk:latest
command: --language fr --model-for-language fr vosk-model-fr-0.22 --data-dir data
volumes:
- /home/server/projects/vosk/data:/data
environment:
- TZ=Europe/Paris
ports:
- 12101:12101
restart: unless-stopped
Merci d’avance ![]()
je dois passer à coté de quelque chose meme en lisant la doc sur github à ce sujet.
Hello,
Pour l’addon HAOS, c’est le port 10300 qui est utilisé.
A mon avis, le commande doit ressembler à celle de whisper
rhasspy/wyoming-addons: Docker builds for Home Assistant add-ons using Wyoming protocol (github.com)
Et n’hésite pas à demander à Mike ![]()
1 « J'aime »
parfit merci, j’ai laissé que language fr qui m’a pris le small par defaut + config le port 10400 vers 10300 car j’ai deja whisper qui tourne sur le 10300 ca marche impec et dans les 2s qui suivent ![]()
1 « J'aime »
Oui, vosk change la donne pour les Frenchy users ![]()
Rien à voir avec Whisper qui reste optimisé pour la langue de Shakespeare.
Le modèle de base est suffisant pour toutes les commandes de base
yes ![]()
par contre j’arrive pas a choisir un autre modele, même en spécifiant « –model-for-language fr vosk-model-fr-0.22 » j’obtient une belle 404 dans les logs quand je sollicite l’assisant vocale
ERROR:asyncio:Task exception was never retrieved
vosk | future: <Task finished name='wyoming event handler' coro=<AsyncEventHandler.run() done, defined at /usr/local/lib/python3.11/dist-packages/wyoming/server.py:28> exception=<HTTPError 404: 'Not Found'>>
vosk | Traceback (most recent call last):
vosk | File "/usr/local/lib/python3.11/dist-packages/wyoming/server.py", line 35, in run
vosk | if not (await self.handle_event(event)):
vosk | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
vosk | File "/usr/local/lib/python3.11/dist-packages/wyoming_vosk/__main__.py", line 285, in handle_event
Mais si tu me dis que le small suffit pour le commun des mortelles ca me va ![]()
Edit: je voulais tester aussi ce small qui est proposé « vosk-model-small-fr-pguyot-0.3 » mais j’ai pas pu du coup ^^
Edit 2: Ah ok fallait le download a la mano dans le repertoire ou il y avait deja le small qui s’etait auto download. J’ai laissé celui de pguyot ca m’a l’air très rapide, l’action était instantanée
Entre les 2 small j’ai un léger soucis c’est que slon les verbes utilisés, il me les met en ‹ ez › et HA ne comprend pas x)
genre ‹ allumer le bureau › devient ‹ allumez le bureau › et HA ne fait rien du coup
Avec l’autre small 0.3 ca me le transforme en ‹ allumé › ^^, donc pareil il ne se passe rien
Doncje dis allume ou meme demarre car il comprend encore mieux ce verbe
Edit 3: Ah bah celui de 1.5go est aussi instantanée finalement. C’est une tuerie ![]()
1 « J'aime »