J’ai réactivé l’intégration auto_backup fournie via HACS avec écriture sur sur un répertoire de mon NAS Synology.
Mais je me demande que faire de la sauvegarde standar HA ?
Puis je la paramétrer en : pas de sauvegardes vu que Auto_backup m’en fait une sur le NAS ?
Ou vaut il mieux la conserver mais en écriture locale uniquement ? ce qui me semble plutot bien, la sauvegarde NAS étant là surout en cas de perte du stockage du serveur.
J’ai aussi activé la sauvegarde générationnelle de auto_backup.
Et qui de la gestion des ancienne sversions ?
auto_backup est censé faire le nettoyage, mais le fait il « automatiquement » ou faut il lancer le service auto backup.purge pour que ça se purge ?
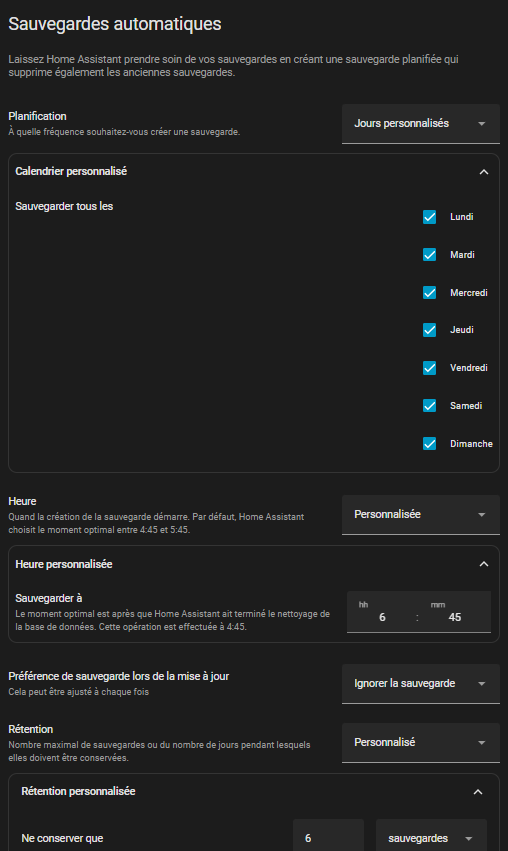
et quid des sauvegardes standard locale ? il y a un paramètre qui permet de dire « ne conserver que » xx versions ou jours, mais on dirait que ça n’efface pas les fichiers de sauvergardes ! Mon disque local de 1To est quasi plein et pour les effacer via HA c’est une par une ! un peu fastidieux !
Bref il y a beaucoup de possibilités mais au final je suis pas sûr d’avoir compris toutes les subtilités.
Bonjour @bemo47
je trouve très pratique la sauvegarde automatique de HA, qui garde bien le nombre demandé de sauvegardes, je les fait aussi sur Synology, bien penser à conservé la clé de cryptage.
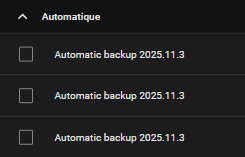
Sinon tu peux supprimer plusieurs sauvegardes depuis HA encochant cette petite coche.
Ah, ça me semble bien gros effectivement, il y a un bon tuto qui explique comment on analyse plus en détail ou sont les gros volumes ?
J’ai pourtant exclu les médias des backup, en plus je dois pas en avoir beaucoup, à moins que les caméras stockent les images ? J’ai pas bien fait attention à ça. J’ai pas frigate, juste les caméras affichées dans des cartes entités images.
et bien voilà, gemini a fait le boulot, ces IA sont quand même au top, et elles ont sacrément évolué en peu de temps… est-ce inquiétant ? je sais, pour l’instant c’est top
Donc j’ai fait du ménage, SQLite est passé de 1.7 Go à 944 Mo ce qui est déjà très bien, rétention réduite à 6 jours.
Et InfluxDB, déjà j’ai compris que je ne l’utilise QUE pour Grafana, et encore un seul graphe sur l’évolution des taux humidité, températures, dew point etc…
On a donc appliqué ce config.yaml :
include:
domains:
- sensor
# 3. LE PLUS IMPORTANT : Nettoyage des métadonnées
# Cela empêche la création des colonnes "_str" que nous avons vues (friendly_name, icon...)
ignore_attributes:
- friendly_name
- icon
- device_class
- state_class
- unit_of_measurement
- source_type
- attribution
- options
Pour ne conserver que le strict nécessaire
Tout ça dans une 2ème base créée from scratch, data essentielles migrées une par une, et nouvelle rétention passée à 5 ans, à voir le taux de grossisement à l’usage et éventuellement réactualiser.
Résultat : 3.7Go avant avec environ 1 an d’historique, 1go maintenant après migration.
A noter que les données kWh font presque le Go à elles toutes seules.