Tout d’abord, je tiens à préciser que j’ai basculé sur HA vraiment tout récemment car Jeedom commençait à sérieusement me gonfler. Je tiens à préciser que je suis une grosse quiche complètement inexistant niveau programmation.
Le coté positif, c’est que je m’éclate avec HA. J’ai inclus une quarantaine de modules en Mqtt et lorsque je fais une automatisation, tout fonctionne de suite, c’est carrément le panard…
Je me suis donc attaqué à Assist, et ça fait des jours que je suis dessus.
J’ai tout d’abord essayé l’Atom echo, puis en satellite avec un Rpi4 et un Respeaker 4 micros array que j’avais au fond d’un tiroir datant de Snips avec Jeedom.
Ben, j’ai le même problème avec les 2:
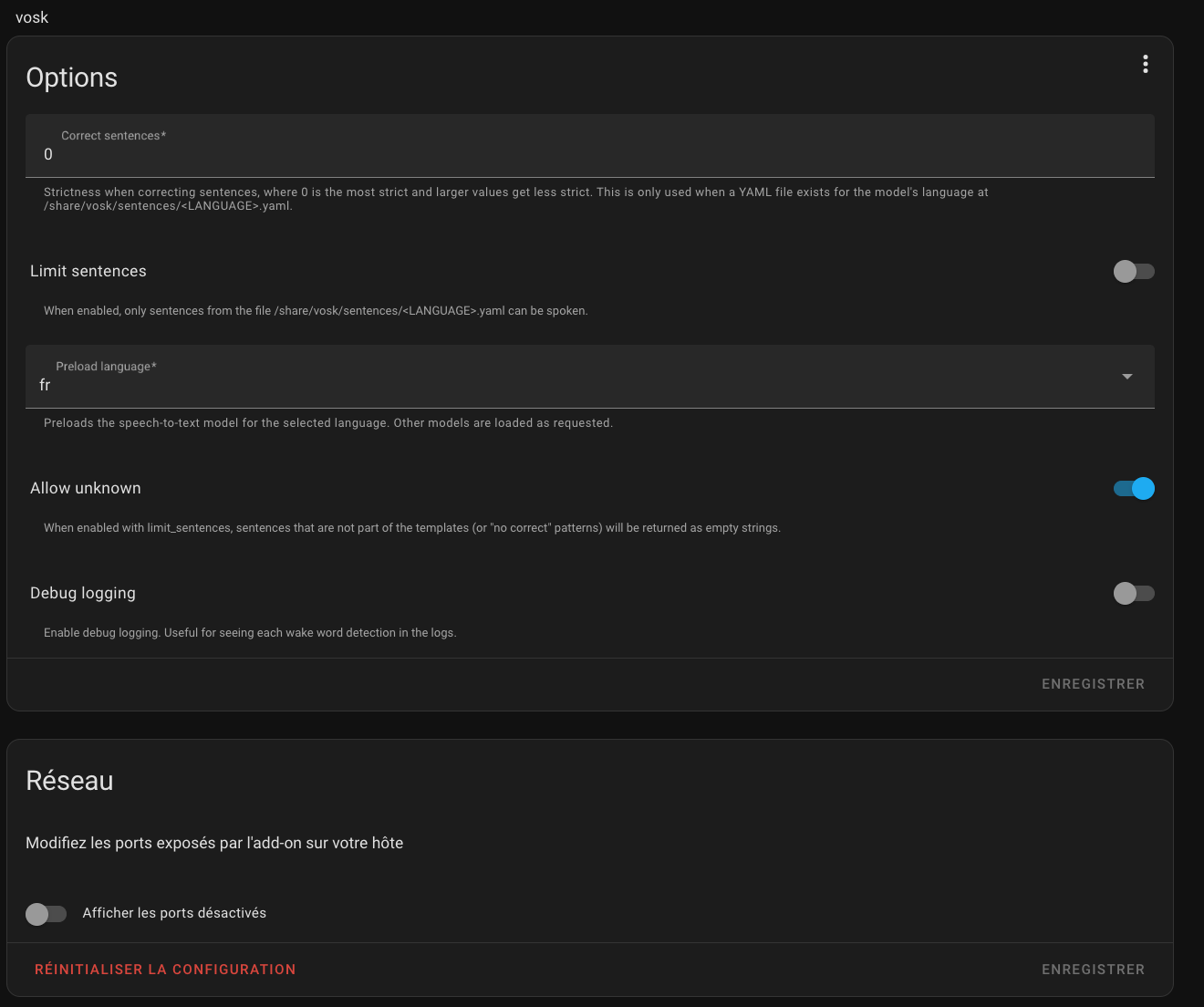
Le mot de réveil est juste excellent avec Snowboy mais Vosk ne comprends rien du tout malgré des alias à tout va. Dans le debug, il répond chaque fois à côté du style « mode nuit » il va comprendre « monde de la nuit ». Pour dire, même si je dis juste 2 mots comme ferme ou éteint « volet cuisine » il répond « j’ai voler la cuisine » Je veux bien avoir un accent prononcé du sud de la France, mais quand même !
J’ai lu un tas de tutos sur les installations d’Assist que j’ai du recommencer 50 fois car je me disais que j’avais certainement merdé quelque part.
Vu ce que tu as déjà mis en place avec Assist , tu es loin d’être une quiche
Utilisateur de vosk depuis le premier jour ( merci Mike de Nabu Casa) je n’ai jamais eu ce type de symptômes, même avec mon accent breton, sauf pour des mots souvent très proches ( éteins, étends) , mais pour le contourner suffit d’être un peu plus poli du type " peux-tu éteindre …" « Peux tu fermer les volets »…etc
En fait VOSK est effectivement très rapide, mais aussi très approximatif. Perso je tourne avec faster-whisper avec le modèle medium. Plus lent, mais plus précis donc pas obligé de perdre du temps à répéter.
Le seul moyen d’avoir une bonne précision avec vosk est d’utiliser un modèle large, mais ça se fait au prix d’utilisation de beaucoup de RAM.
Big models are for the high-accuracy transcription on the server. Big models require up to 16Gb in memory since they apply advanced AI algorithms
Tu as en partie raison, mais les sources que tu indiques ne sont vraiment valables que pour le modèle English, faster Whisper ayant été conçu et optimisé dans cette langue.
Langue qui n’a pas du tout les mêmes subtilités que la langue de Molière
Vosk fonctionne beaucoup mieux pour beaucoup d’autres langues et est plus accurate à ressources égales .
Aucun pb pour Vosk avec les sentences natives de HA sauf qu’il faut meubler un peu dans certains cas pour lui éviter des confusions
Bon , à moins que tu ais un accent très très marqué ( pire que @WarC0zes ) , je vois pas où ça peut coincer.
On peut essayer de trouver une piste en y allant par élimination.
On va déjà tester sans satellite.
Qu’est ce que ça donne sur un pc ou via l’appli companion ?
Je vais rajouter que j’étais sur RPI 5 et comme ça merdait grave, j’ai tout migré sur un Shuttle I5 que j’avais sur une étagère qui me servait pour Sarah à l’époque. Mais j’ai exactement le même problème sur les 2 machines…
Non pas pire comme accent, j’ai entendu une petite vidéo avec justement un Atom echo et il me semble bien que c’était lui.
lorsque j’écris le texte sur mon mac, ça fonctionne très bien, mais niveau micro, je ne peux pas, j’ai ça :
et avec l’appli companion, je regarde ça demain. Je pars me coucher, demain taf à 5h .
En tous les cas un grand merci pour cette formidable solidarité
Bonne nuit