Bonjour,
Je partage ici un retour d’expérience technique autour d’une architecture Home Assistant un peu atypique, volontairement hors pipeline Assist / Wyoming.
Ce n’est pas une recommandation, mais un REX destiné à discussion.
Comme c’etait un peu délicat d’en faire un article je le poste ici.
Objectif
Tester une approche où :
- Home Assistant reste seul maître des actions
- un LLM local est utilisé uniquement comme moteur de décision
- aucune action n’est déclenchée directement par le LLM
- aucune intégration Assist / STT / TTS n’est utilisée
![]() Le LLM ne parle pas, n’écoute pas directement, n’agit pas.
Le LLM ne parle pas, n’écoute pas directement, n’agit pas.
![]() Il renvoie uniquement un JSON contractuel.
Il renvoie uniquement un JSON contractuel.
Architecture (vue d’ensemble)
Principe général :
- Une phrase est injectée dans Home Assistant via l’événement
conversation.process
(tests faits sans micro, via Outils développeur → Événements) - Une automation filtre les phrases commençant par un mot-clé (
Nestor) - La phrase nettoyée est envoyée via
rest_commandà un service Python local - Ce service appelle un LLM local (Ollama)
- Le LLM renvoie strictement un JSON normalisé
- Home Assistant valide, mappe… ou ignore
Schéma simplifié (joint) :
(schéma volontairement hors pipeline Assist)
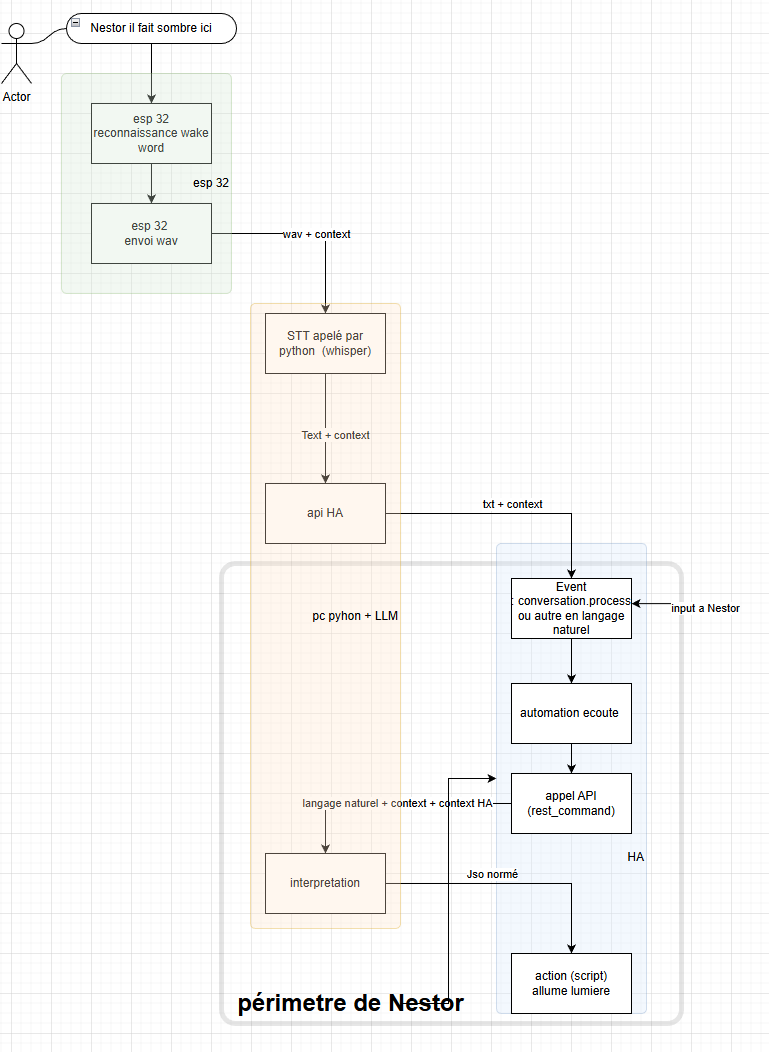
le REX se fait uniquement sur la parie encadré en gris, je ferais la partie « voix » plus tard, la ce qui m’intéresse c’est mettre en place un moteur de décision qui comprends un langage « humain » que ce soit le résultat d’un script, une saisie de texte, un speech to text …qui déclenche quelque chose de cadré (ou un refus) que je peux traiter via HA…
Rôle exact du LLM
Le LLM :
- reçoit une phrase + un contexte synthétique HA
- propose une intention structurée
- ne connaît :
- ni les entités
- ni les
area_id - ni les services HA
Exemple de sortie attendue :
{
"intent": "turn_on_lights",
"confidence": 0.82,
"actions": [
{
"action": "turn_on_lights",
"parameters": { "area": "kitchen" }
}
],
"memory": []
}
Si le JSON est invalide, incomplet ou ambigu → aucune action.
Côté Home Assistant (très résumé)
- Trigger :
conversation.process - Filtrage : regex sur le mot-clé
- Appel :
rest_commandvers API locale - Décision finale :
- whitelist d’intentions
- seuil de confiance
- mapping local zones → entités
- Action : script HA classique (ou rien)
je mets l’automation, les rest command et le script a la fin du post pour les plus curieux
Tout le contrôle reste côté HA.
Implémentation technique (factuelle)
- LLM runtime : Ollama
- Modèle : instruct généraliste (pas de fine-tuning) petite taille (Llama 3:7b)
- Service décision : Python + FastAPI + uvicorn
- Machine : PC dédié (Windows + WSL), GPU RTX 3090
- Docker : non
- Assist / Wyoming / STT / TTS : non utilisés
- Tests : uniquement via
conversation.process
Temps de mise au point (ordre de grandeur) : ~1 journée, principalement pour :
- fiabiliser le JSON
- cadrer le prompt
- gérer les timeouts et échecs propres
Pourquoi cette approche (très brièvement)
- éviter qu’un LLM déclenche directement des actions
- garder une traçabilité totale
- pouvoir désactiver le système en 1 ligne
- accepter l’échec comme comportement normal
Ce n’est pas une alternative à Assist.
C’est une expérimentation autour de la séparation stricte décision / action.
Limites / avertissements
- approche hors des sentiers battus HA
- non adaptée aux débutants (codage python, connaissance réseau, connaissance fonctionnement HA (entrées, gestion des variables…)
- nécessite discipline et garde-fous
- en aucun cas un “assistant vocal clé en main”
Questions ouvertes
- Voyez-vous des risques évidents que je n’aurais pas identifiés ?
- Des améliorations possibles côté HA (validation, mapping, guardrails) ? (notament pour gerer un mapping d’entité dans une zone et les donner séparément dans le JSON, (concretement une façon de faire pour que HA sache quoi faire (si le jason renvoit { area =« kitchen » , action = " turn_on_lights"} ou { area =« bedroom » , action = " turn_on_lights"} il gere switch.lumiere_cuisine ou switch.lumiere_chambre, genre table de correspondance)
- Intérêt ou non de comparer cette approche avec l’intégration Ollama HA ?
Merci d’avance pour vos retours.
Golthar
###Annexes
automation nestor_ecoute
alias: Nestor – écoute vocale
description: Déclenchement principal via conversation.process
mode: single
trigger:
- platform: event
event_type: conversation.process
condition:
- condition: template
value_template: >
{{ trigger.event.data.text | lower | regex_match('^nestor\\b') }}
action:
- variables:
user_input: >
{{ trigger.event.data.text
| regex_replace('(?i)^nestor\\s*', '')
| trim }}
- service: script.nestor_router_decision_area_mapping
data:
user_input: "{{ user_input }}"
script as service pour traiter la réponse
alias: Nestor – router décision (mapping area)
mode: single
variables:
area_map:
kitchen: switch.interrupteur_cuisine
living_room: switch.interrupteur_salon
parent_s_bedroom: switch.interrupteur_chambre_parents
pierre_s_bedroom: switch.interrupteur_chambre_pierre
sequence:
- action: rest_command.nestor_decide
data:
user_input: "{{ user_input }}"
response_variable: nestor_decision
- variables:
has_action: >
{{ nestor_decision is defined
and nestor_decision.content is defined
and nestor_decision.content.actions is defined
and nestor_decision.content.actions | length > 0 }}
action_name: >
{{ nestor_decision.content.actions[0].action
if has_action else '' }}
area: >
{{ nestor_decision.content.actions[0].parameters.area
if has_action
and 'parameters' in nestor_decision.content.actions[0]
and 'area' in nestor_decision.content.actions[0].parameters
else '' }}
target_entity: >
{{ area_map.get(area) if area in area_map else none }}
- choose:
- conditions:
- condition: template
value_template: >
{{ has_action
and action_name == 'turn_on_lights'
and target_entity is not none }}
sequence:
- service: switch.turn_on
target:
entity_id: "{{ target_entity }}"
rest_command dans configuration.yaml
rest_command:
nestor_decide:
url: "http://[IP_LOCALE]:8001/decide"
method: POST
timeout: 60
headers:
Content-Type: application/json
payload: >-
{
"meta": {
"source": "home_assistant",
"version": "nestor-maison-v0",
"timestamp": "{{ now().isoformat() }}"
},
"user_input": "{{ user_input }}",
"context": {
"presence": {
"home": {{ is_state('person.jacques', 'home') | lower }},
"persons": ["jacques"]
},
"sleep": {
"awake": true
},
"time": {
"local": "{{ now().strftime('%H:%M') }}",
"period": "evening"
},
"home_state": {
"lights_on": 0,
"covers_open": 0,
"robot_allowed": true
}
}
}
si le sujet intéresse je mettrais l’archi python sur github (mais c’est tres basique…)
le test :
1 on déclenche l’évènement
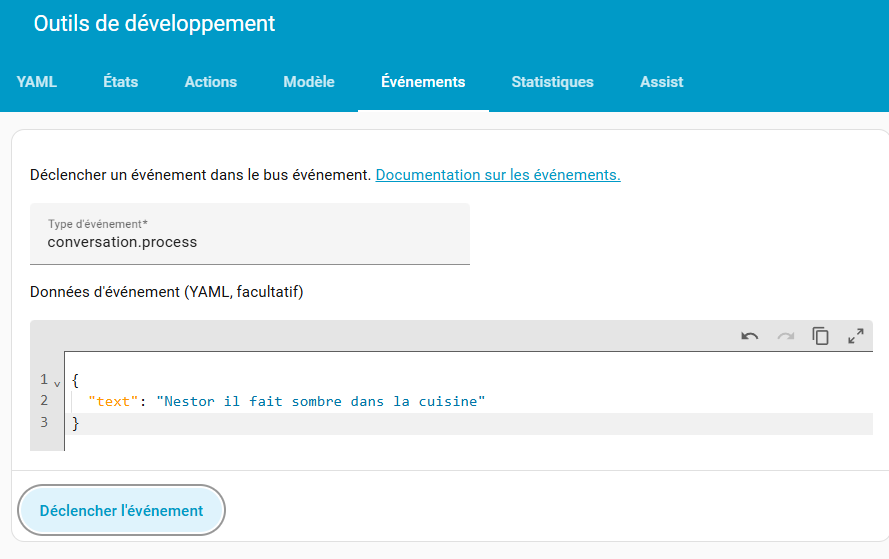
2 une automatisation écoute et envoie via restcommand a l’API python
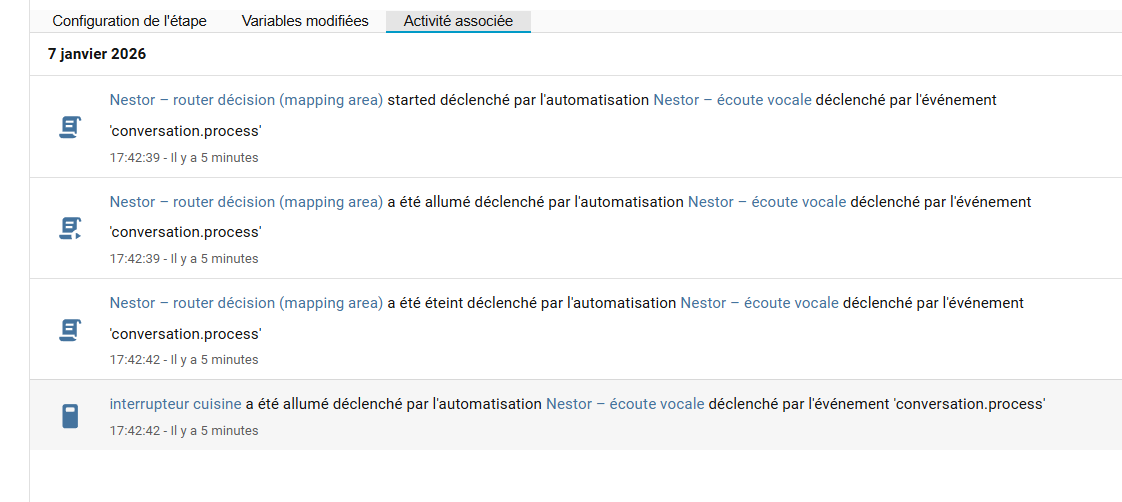
3 le LLM sur une autre machine locale qui répond a l’automatisation en utilisant son json
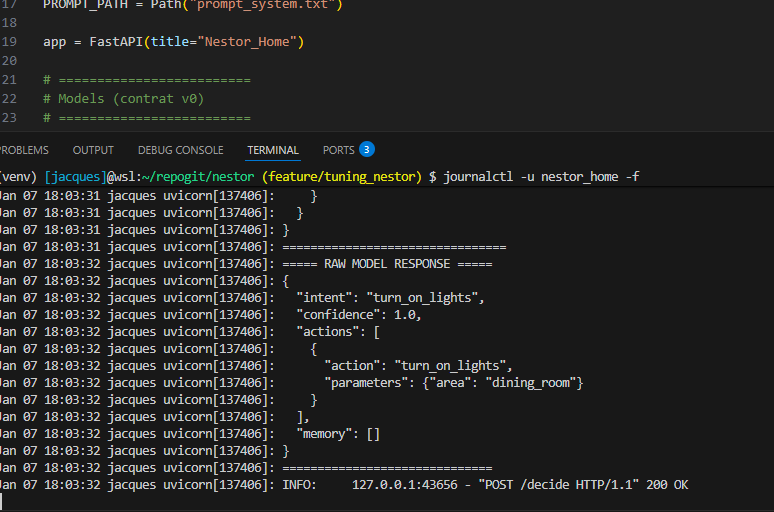
4 le json est interprété par l’automatisation en effectuant l’action : que la lumière soit !