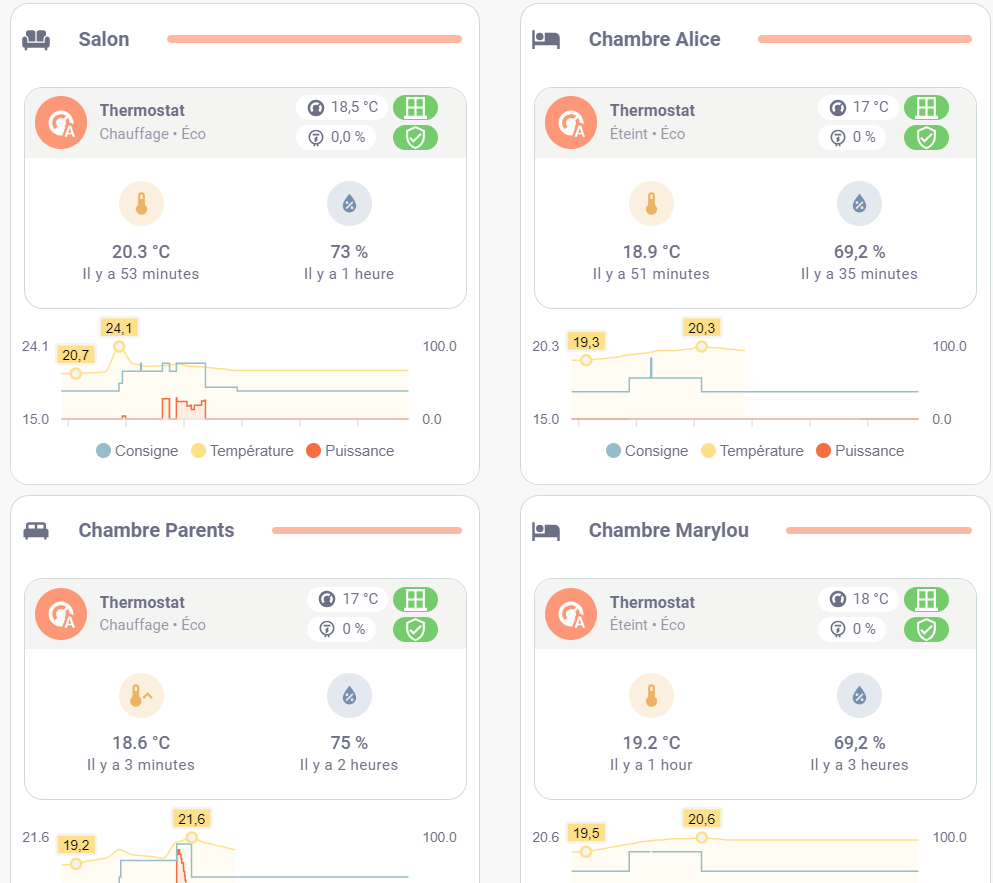
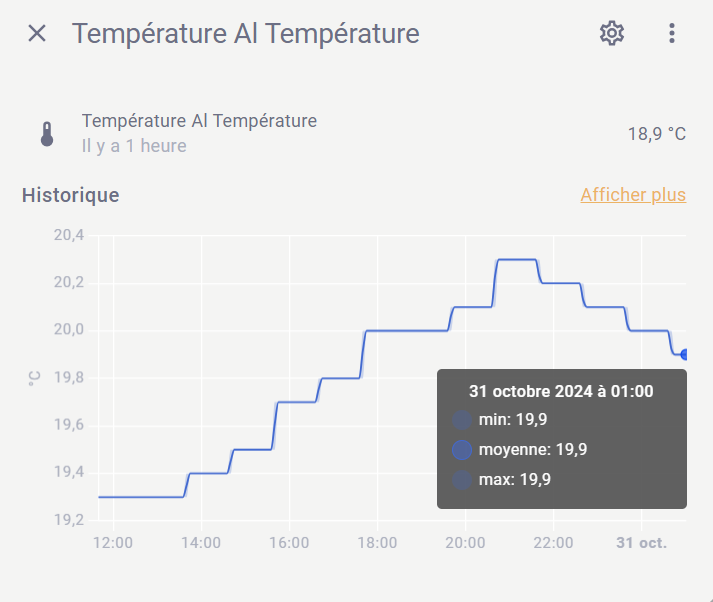
Voici mon problème. De facon régulière mais aléatoire, je perds le rafraichissement des valeurs sur mes graphiques, que ce soit sur apex ou minigraph card par exemple.
On voit bien que je n’ai plus de stats depuis ce même moment, alors que le sensor en lui même affiche la bonne valeur actuelle.
Pour débloquer la situation, je redémarre home assistant, et tout repars, pour un certain temps.
En fouillant un peut j’ai cru comprendre à une saturation de la base de donnée. J’ai donc ajouté dans mon fichier configuration un filtrage des sensors qui me semblaient les plus gourmands :
Je n’ai rien vu de probant. J’ai supprimé mon sensor.temperature.maison pour voir ce que cela donne. Pour le moment pas de nouveau plantage, mais c’est aléatoire.
Salut
La seule saturation envisageable c’est la limite de l’espace de stockage => 50go. Avec 16go utilisés actuellement, tu as de la marge.
Par contre, regarde si tu n’as pas un message à propos de la mauvaise santé ou corruption de la base.
Hello !
Donc pour le coup, ça serait plus un plantage plutôt qu’une saturation.
ma dernière capture, il n’y avait pas toutes les infos au niveau du recorder puisqu’il était sur « timout »
Donc après reboot voici ce que j’ai quand cela fonctionne :
System Information
version
core-2024.10.4
installation_type
Home Assistant OS
dev
false
hassio
true
docker
true
user
root
virtualenv
false
python_version
3.12.4
os_name
Linux
os_version
6.6.54-haos
arch
x86_64
timezone
Europe/Paris
config_dir
/config
Home Assistant Community Store
GitHub API
ok
GitHub Content
ok
GitHub Web
ok
HACS Data
ok
GitHub API Calls Remaining
4986
Installed Version
2.0.1
Stage
running
Available Repositories
1467
Downloaded Repositories
51
Home Assistant Cloud
logged_in
false
can_reach_cert_server
ok
can_reach_cloud_auth
ok
can_reach_cloud
ok
Home Assistant Supervisor
host_os
Home Assistant OS 13.2
update_channel
stable
supervisor_version
supervisor-2024.10.3
agent_version
1.6.0
docker_version
27.2.0
disk_total
50.5 GB
disk_used
17.0 GB
healthy
true
supported
true
host_connectivity
true
supervisor_connectivity
true
ntp_synchronized
true
virtualization
kvm
board
ova
supervisor_api
ok
version_api
ok
installed_addons
Terminal & SSH (9.15.0), Mosquitto broker (6.4.1), Z-Wave JS UI (3.16.1), Home Assistant Google Drive Backup (0.112.1), AdGuard Home (5.1.4), ESPHome (2024.10.2), Vaultwarden (Bitwarden) (0.23.2), Studio Code Server (5.17.2), Zigbee2MQTT (1.41.0-1), Music Assistant Server (2.3.2), Cloudflared (5.2.0), TubesZB Zigpy-CLI Tools (0.3.1.0), SQLite Web (4.2.2), Frigate Proxy (1.5)
Dashboards
dashboards
4
resources
38
views
27
mode
storage
Recorder
oldest_recorder_run
24 octobre 2024 à 09:07
current_recorder_run
2 novembre 2024 à 18:37
estimated_db_size
910.27 MiB
database_engine
sqlite
database_version
3.45.3
Pour le moment pas pu reproduire, mais comme j’ai eu des maj avec reboot je pense que le recorder n’a pas eu le temps de replanter.
Et pour toi @Pulpy-Luke cela ne pourrait pas venir de mon ancien sensor.temperature_maison qui recordait de trop ?
C’est assez simple.
Tu fais la liste de ce que tu veux exclure, soit. Donc tout ce qui n’est pas dans cette liste est inclus.
Par exemple image.* ne fait pas partie de tes exclusions.
Indirectement, j’ai toujours dit que mettre tout par défaut dans la base, c’est tout sauf une bonne solution. En principe, tu devrais être en mesure de dire ce dont tu te sers. Et donc de faire l’inverse (faire une liste de ce que tu veux inclure). Là au moins, tu n’as jamais de souci
Oui tu as raison. Avec le réseau grandissant, il va falloir que je m’y penche.
Mais pour ma culture, il me semble que sur une entité zigbee, on peut limiter le nombre de requêtes et de remontées. Est-ce possible de limiter d’autres entités, notamment ici par exemple Frigate sans forcément les exclure ?
Pour le zigbee comme pour le reste je n’ai pas d’expérience sur une limitation du nombre de remontée.
Et puis si tu arrives à dire que plutôt que toutes les minutes, une valeur tous les quarts d’heure c’est suffisant, il n’y a qu’un pas pour dire que les données d’historiques ne servent pas.
Ne pas avoir d’histoire ça ne veut pas dire ne pas avoir la valeur en cours
Bon par contre je ne m’en sors pas. Le disque étant saturé, je n’arrive à rien.
J’ai donc provisoirement augmenté l’espace disque.
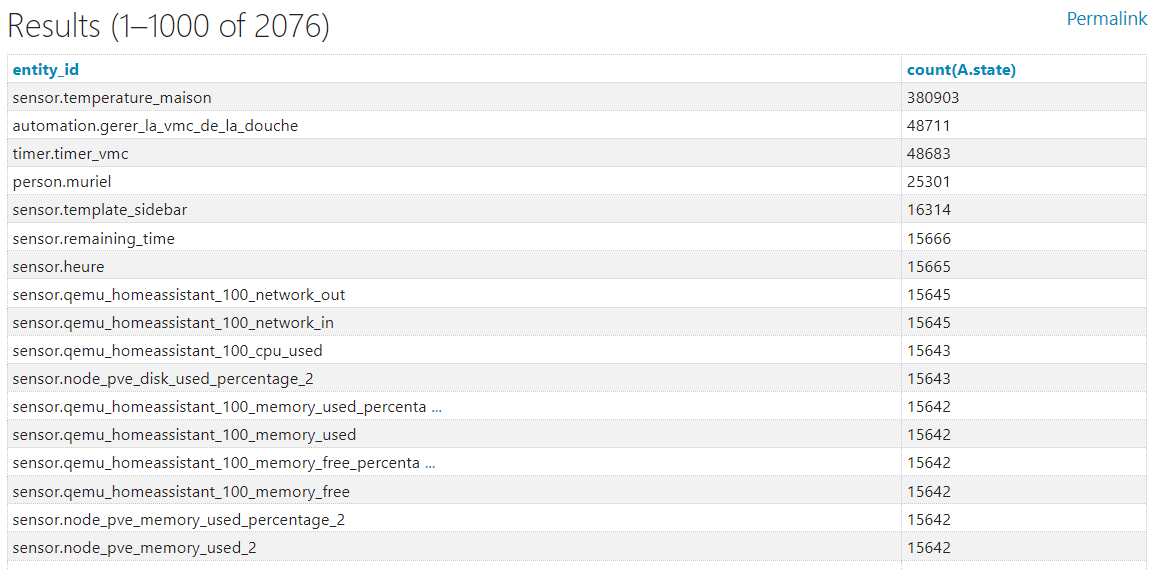
Mais sur sqlite je n’arrive pas à exécuter la commande pour voir mes x entités qui polluent :
SELECT B.entity_id, count(A.state)
FROM states as A
JOIN states_meta as B on B.metadata_id = A.metadata_id
GROUP BY B.entity_id
ORDER by count(A.state) DESC
sqlite plante au bout de quelques minutes.
J’ai essayé de purger la base de donnée dans les actions, mais elle ne bouge pas en taille. j’ai même essayé de conserver seulement 1 jour, mais cela ne passe pas non plus.
Edit :
J’ai essayé de télécharger la base de donnée avec files dans ha, elle est bien donnée à 20Go, mais quand je la télécharge le fichier est de 1ko, comme si il était corrompu
Hello,
Bon bah j’ai du restaurer une sauvegarde sous proxmox parce que c’était de pire en pire. Du coup je viens de supprimer le fichier et repartir de zero. Tant pis pour mon historique à long terme.
Je suis en train en // de faire la méthode d’inclure uniquement ce que je souhaite, mais c’est du travail de fourmis
Je vous tiens au courant.