Prérequis: compétences SQL et excel
Comme beaucoup, je suis fan de graphique, de données précises sur les différents éléments que l’on peut compatibiliser.
Et comme beaucoup, en arrivant sur un nouveau système, en intégrant de manière différente un indice de conso ou de production, je suis frustré de perdre l’historique.
Je me suis donc penché sur cette problématique et je me suis aidé du tuto de remi81 (rémi, c’est quoi ton pseudo sur le forum ?) pour mettre en place les outils dont j’avais besoin.
https://domo.rem81.com/2020/12/17/home-assistant-deporter-la-base-de-donnees/
En l’état, une fois l’install de mariaDB puis de phpmyadmin, on a accès à la BDD de HA.
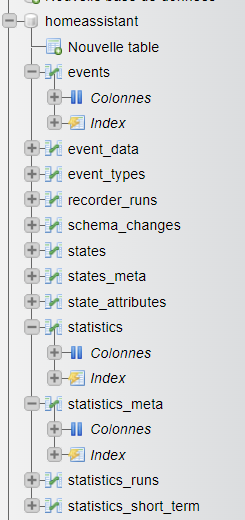
Deux tables nous intéressent:
- statistics_meta qui contient les index des différentes métriques identifiées par HA.
- statistics qui contient, pour chaque métrique, les valeurs pour chaque laps de temps
Mon problème:
- ajouter mes données de production photovoltaïques depuis 2010
- ajouter mes données grdf en bypassant la contrainte actuelle de l’event call_grdf du fait du capcha de la page grdf.
L’exercice étant quasi identique, je vais décrire le processus du premier problème.
- Ajouter un index spécifique à ma production PV dans la table statistics_meta
Cette table contient 4 colonnes essentielles pour notre besoin:
id: l’index de la donnée
statisctics_id: le nom du sensor qui sera utilisé dans HA
source: valeur par défaut recorder, mais on y trouve aussi linky (j’ai donc pris ce dernier)
unit_of_measurement: comme son nom l’indique, l’unité de mesure. En l’occurence, on a le Wh qui est tout indiqué pour mon besoin, mais pour des données de conso d’eau, on prendra le m3, of course !
Processus:
On va commencer par chercher le dernier id de la table:
Via le bouton SQL
vous exécutez la requête:
SELECT max(id) FROM statistics_meta ;
La valeur résultat est le dernier id référencé (par exemple, 92, chez moi). Il faudra faire +1 pour insérer votre nouvel élément (soit 93 pour moi).
Ensuite, pour ajouter une ligne, il suffit de la copier, puis de la modifier
ex: je copie la ligne de conso d’énergie (notez l’id 86)
puis vous renseignez/éditez les champs
Mettre le nouvel id (chez moi, 93), renseignez le nom du nouveau sensor , l’unité de mesure et donner lui un petit nom (comme sous HA quand on veut mettre un nom plutôt que le sensor)
Une fois validé, vous avez créé un nouvel élément.
L’id et le statistics_id seront réutilisés dans la table statistics
- Ajouter les données de production PV dans la table statistics
Dans la table statitics, on aura des champs essentiels (les autres restent à NULL pour nos indices de conso/prod)
- id: identifiant de l’enregistrement. attention, il ne s’agit pas de l’id de la table précédente.
- created_ts : la date de création de l’enregistrement au format unixtimestamp (j’y reviendrais plus tard)
- metadata_id: l’identifiant du sensor . C’est l’id qu’on retrouve dans la table statitics_meta
- start_ts: la date associée à la valeur de l’instant t, au format unixtimestamp
- state : la valeur de l’instant t
- sum : la valeur cumulée depuis le début
Vous avez compris, on doit ajouter nos données historiques ici !
Et la meilleure solution, c’est de les importer
Ca tombe bien, phpmydamin supporte deux types principales d’importations: le csv et le sql. Pour ma part, j’ai choisi le csv.
le format d’import doit respecter les champs suivant:
id,« created »,« created_ts »,« metadata_id »,« start »,« start_ts »,« mean »,« min »,« max »,« last_reset »,« last_reset_ts »,« state »,« sum »
où on retrouve les champs décrits ci-dessus (pour les autres, vous mettrez la valeur NULL)
Deux problèmes: l’id et le format unixtimestamp
Pour l’id, il nous faut absolument un id non utilisé. Et comme on va en ajouter un wagon, il faut se donner de la marge ,car HA risque d’alimenter la table pendant vos tâtonnements (j’étais à l’id 6000, j’ai commencé à importer à partir du 10000, et j’ai fini à l’indice 700000)
On va utiliser une requête similaire à celle mise plus haut
SELECT max(id) FROM statistics;
Une fois la valeur obtenue, ajouté de la marge (au moins 3000 de plus) et utilisez cette valeur comme premier id de votre liste d’enregistrement.
Pour la date au format unixtimestamp, la solution la plus facile (y en a d’autres) c’est de convertir la première date de vos enregistrements historiques (par ex: le 01/01/2010 00:00:00) .
Ca, c’est facile, il suffit d’aller ici: https://www.unixtimestamp.com/
Vous obtenez alors une date en nombre de secondes depuis le 1/1/1970.
L’autre méthode, sous excel, par exemple, c’est de mettre la formule: = (C2-DATE (1970;1;1)) * 86400 (à adapter : C2 est la cellule qui contient ici la date au format classique)
Puis d’incrémenter pour les évènements suivant, en nombre de seconde d’écart: - si c’est toutes les dix minutes, +600
- si c’est toutes les demi-heures, +1800

A priori, vous devez avoir les données suivantes dans votre historique perso (non home assistant): date , valeur et généralement, vous avez ces infos de manière régulière (moi, c’est toutes les 10 minutes, donc 6 par heure)
Il va vous falloir construire votre fichier csv pour transformer cette masse de donnée en données compréhensibles par phpmyadmin (donc au format id,« created »,« created_ts »,« metadata_id »,« start »,« start_ts »,« mean »,« min »,« max »,« last_reset »,« last_reset_ts »,« state »,« sum »
J’utilise un fichier excel avec les colonnes kivonbien
id: la valeur de l’identifiant du 1er enregistrement, puis, +1 à chaque enregistrement suivant
created: NULL
created_ts: la date au format unixtimestamp => vous avez vu pour la transformation Mais il faut ajouter 1.000001 à cause d’un problème de clé dupliquée (va comprendre pourquoi ?!)
metadata_id : l’identifiant de votre sensor (chez moi, 93)
start: NULL
start_ts: l’heure de votre enregistrement, cad l’unixtimestamp trouvé précédemment (sans l’ajout de 1.000001, mais avec les +600 ou +1800 ou autre pour chaque enregistrement)
mean: NULL
min: NULL
max: NULL
last_reset: NULL
state: la valeur en Wh (ce qui suppose une conversion si vous avez par exemple, une valeur en W toutes les 10 minutes: il faut diviser par 6, si vous avez une valeur en kW toutes les demi-heures, il faut multiplier par 1000 et diviser par 2)
sum: la somme de state et de la sum de l’enregistrement précédent
Une fois votre excel rempli, vous le sauvergardez en .csv
Mais c’est pas fini:
En région france, le csv a pour séparateur le point-virgule, alors que phpmyadmin attends une virgule
J’ouvre donc le csv avec notepad pour remplacer les « ; » par des « , »
Voila ! le csv est prêt !
Vous avez plus qu’à l’importer!
Pour gagner du temps dans l’import, je désactive le contrôle des clés étrangères et j’active le « Mettre à jour les données lorsque des clés dupliquées sont trouvées lors de l’importation (ajouter ON DUPLICATE KEY UPDATE) »
Vous cliquez sur importer et ca se lance. ca va prendre du temps …
Attention: quand charge beaucoup d’éléments un time out entraine l’arrêt de l’import au bout d’un certain temps (moi, c’est à peu près toutes les 15000 lignes)
je dois alors recharger l’import en ayant éliminé les données déjà rentrées dans le csv
=> une petite requête SQL vous donne le dernier id rentré
SELECT MAX(id) from statistics WHERE metadata_id=93;
(vous remplacez 93 par l’index de votre sensor)
Ca vous donne l’index du dernier enregistrement importé et vous supprimez les lignes du csv correspondantes avant de relancer l’import
Amusez vous bien !
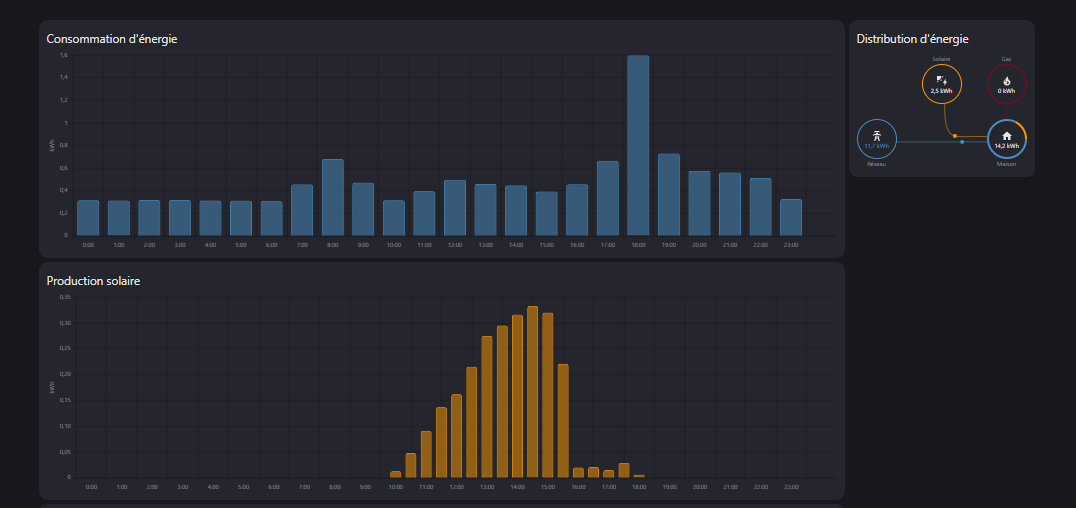
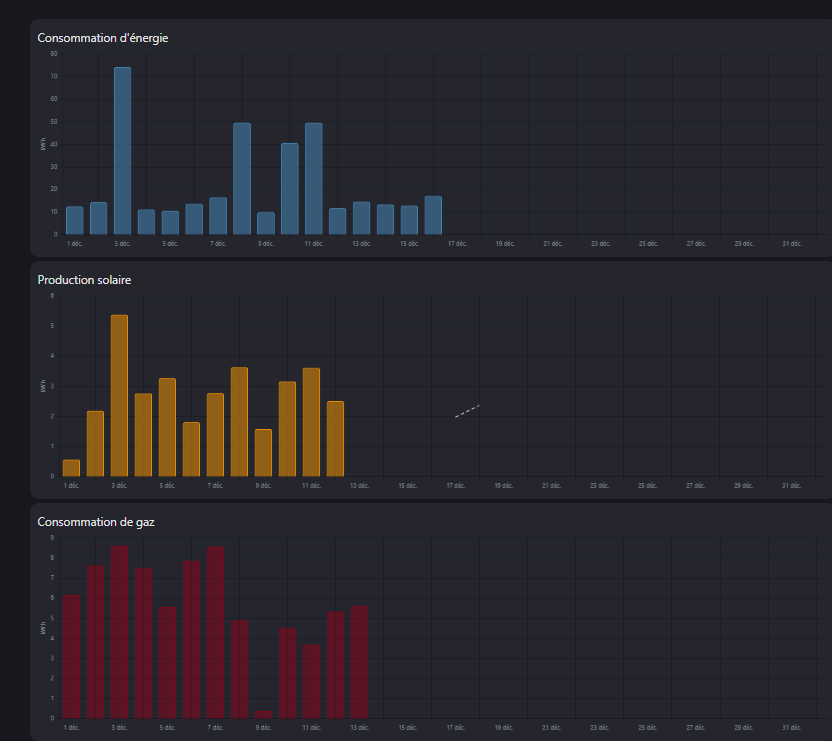
Voila ce que cela donne chez moi