Bonjour à tous,
Je viens de me lancer dans l’utilisation de la voix sur HA , aprés des résultats assez décevant en utilisant WHISPER comme STT, je tente l’utilisation de VOSK qui fait l’objet de bons résultats.
Cependant, aprés installation de l’add-on, config, démarrage… je ne trouve pas VOSK comme intégation et ne peux donc l’utiliser.
Toute aide bienvenue.
Logs VOSK
s6-rc: info: service s6rc-oneshot-runner: starting
s6-rc: info: service s6rc-oneshot-runner successfully started
s6-rc: info: service fix-attrs: starting
s6-rc: info: service fix-attrs successfully started
s6-rc: info: service legacy-cont-init: starting
s6-rc: info: service legacy-cont-init successfully started
s6-rc: info: service vosk: starting
s6-rc: info: service vosk successfully started
s6-rc: info: service discovery: starting
LOG (VoskAPI:ReadDataFiles():model.cc:213) Decoding params beam=13 max-active=7000 lattice-beam=4
LOG (VoskAPI:ReadDataFiles():model.cc:216) Silence phones 1:2:3:4:5:6:7:8:9:10
LOG (VoskAPI:RemoveOrphanNodes():nnet-nnet.cc:948) Removed 0 orphan nodes.
LOG (VoskAPI:RemoveOrphanComponents():nnet-nnet.cc:847) Removing 0 orphan components.
LOG (VoskAPI:ReadDataFiles():model.cc:248) Loading i-vector extractor from /data/vosk-model-small-fr-0.22/ivector/final.ie
LOG (VoskAPI:ComputeDerivedVars():ivector-extractor.cc:183) Computing derived variables for iVector extractor
LOG (VoskAPI:ComputeDerivedVars():ivector-extractor.cc:204) Done.
LOG (VoskAPI:ReadDataFiles():model.cc:282) Loading HCL and G from /data/vosk-model-small-fr-0.22/graph/HCLr.fst /data/vosk-model-small-fr-0.22/graph/Gr.fst
LOG (VoskAPI:ReadDataFiles():model.cc:308) Loading winfo /data/vosk-model-small-fr-0.22/graph/phones/word_boundary.int
INFO:root:Ready
[18:58:07] INFO: Successfully sent discovery information to Home Assistant.
s6-rc: info: service discovery successfully started
s6-rc: info: service legacy-services: starting
s6-rc: info: service legacy-services successfully started
Salut,
Effectivement aprés un peu d’attente et un redémarrage, tout est OK.
Ce modéle est vraiment, vraiment, vraiment beaucoup plus rapide est performant que Whisper
Merci
C’est bien pour ça qu’après en avoir été le premier Frenchy user/testeur dès que Mike a mis à dispo ce nouvel Addon je l’ai recommandé dans presque tous les sujets abordant Assist dans ce Forum.
Amuse toi bien
PS: et ne t’embête pas avec des modèles plus larges… histoire de garder de la ressource pour un futur LLM bien intégré et local.
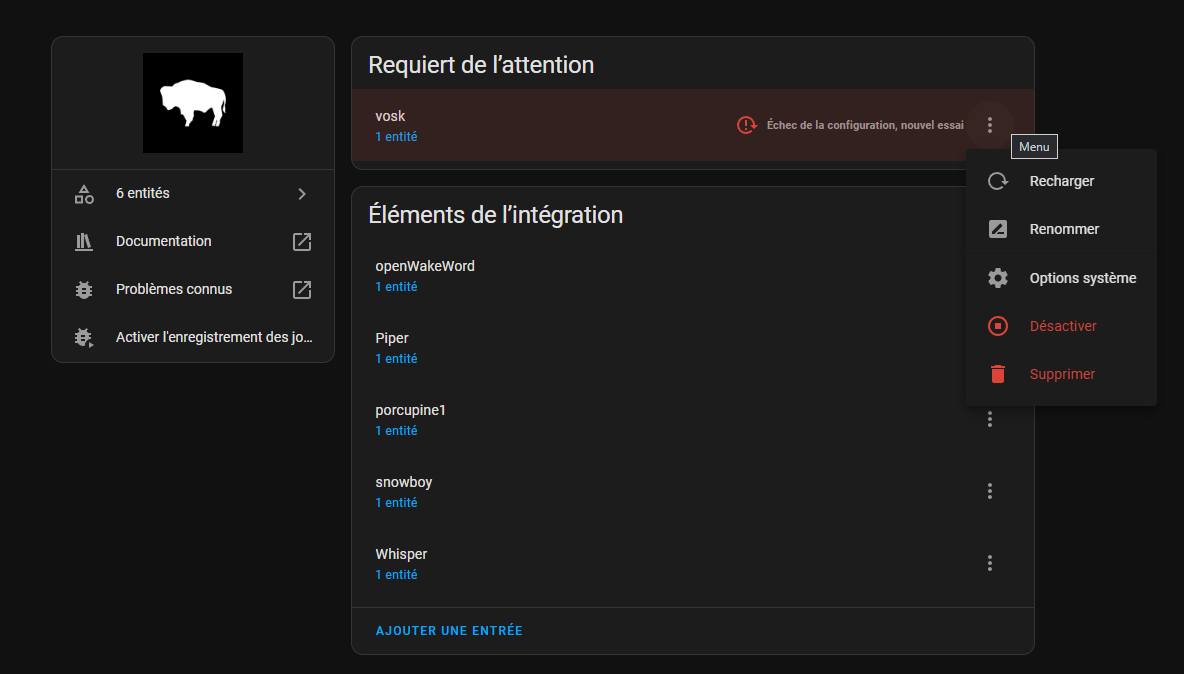
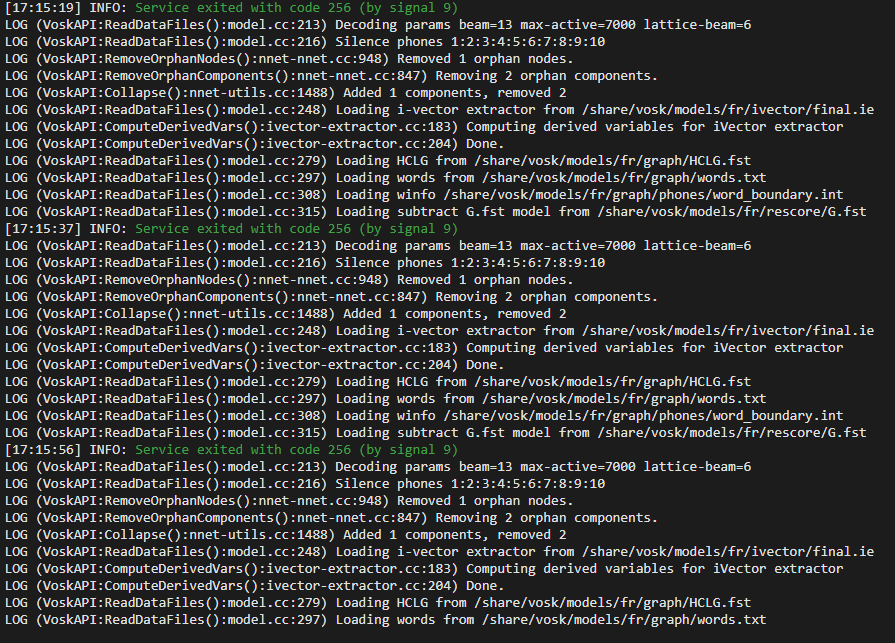
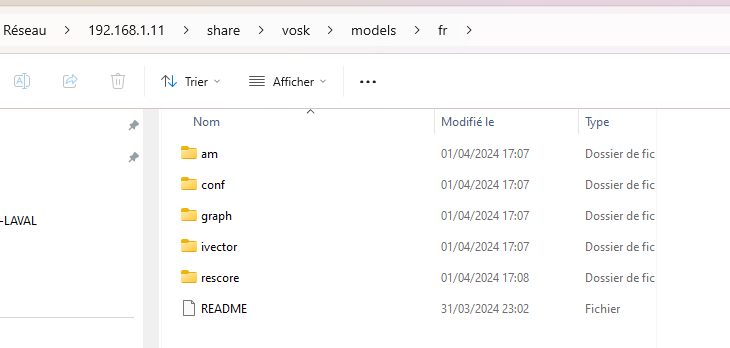
jai copié les fichiers dans share / vosk/ models fr et depuis j’ai les logs suivants et echec de la configuration dans wyoming. Un truc à faire en plus?
As tu déjà essayé sans installer de fichier vosk personnalisé ( pas de dossier vosk dans share) ?
Si tu indiques fr dans la conf de vosk, il chargera automatiquement un modèle fr de base.
Le dossier share/vosk permet d’utiliser des modèles plus larges
je viens de tester: j’ai arrété vosk, supprimé le dossier complet dans share puis j’ai démarré vosk, il démarre rapidement et est fonctionnel. J’ai régardé il est bien configuré en fr dans configuration.
Le modele que j’avais mis dans share est vosk-model-fr-0.6-linto-2.2.0, peut être trop gros?
Je suis sur une HA yellow 2GB RAM, 32GB
ah ok, c’est bête ça, je pensais que ça passait. Tant que j’y suis autre question, sur microphone assist, dans configuration mon micro est bien sélectionné mais ça ne pas l’air de fonctionner, il y a il un moyen de le tester?
Salut,
ta pas fais attention a ce message sur la page de download
Citation
Le petit modèle mesure généralement environ 50 Mo et nécessite environ 300 Mo de mémoire lors de l’exécution. Les grands modèles sont destinés à la transcription de haute précision sur le serveur. Les gros modèles nécessitent jusqu’à 16 Go de mémoire car ils appliquent des algorithmes d’IA avancés. Idéalement, vous les exécutez sur des serveurs haut de gamme comme i7 ou le dernier AMD Ryzen. Sur AWS, vous pouvez jeter un œil aux machines c5a et aux machines similaires dans d’autres cloud.