Personnellement je procède de la manière ci-dessous qui est certainement perfectible :
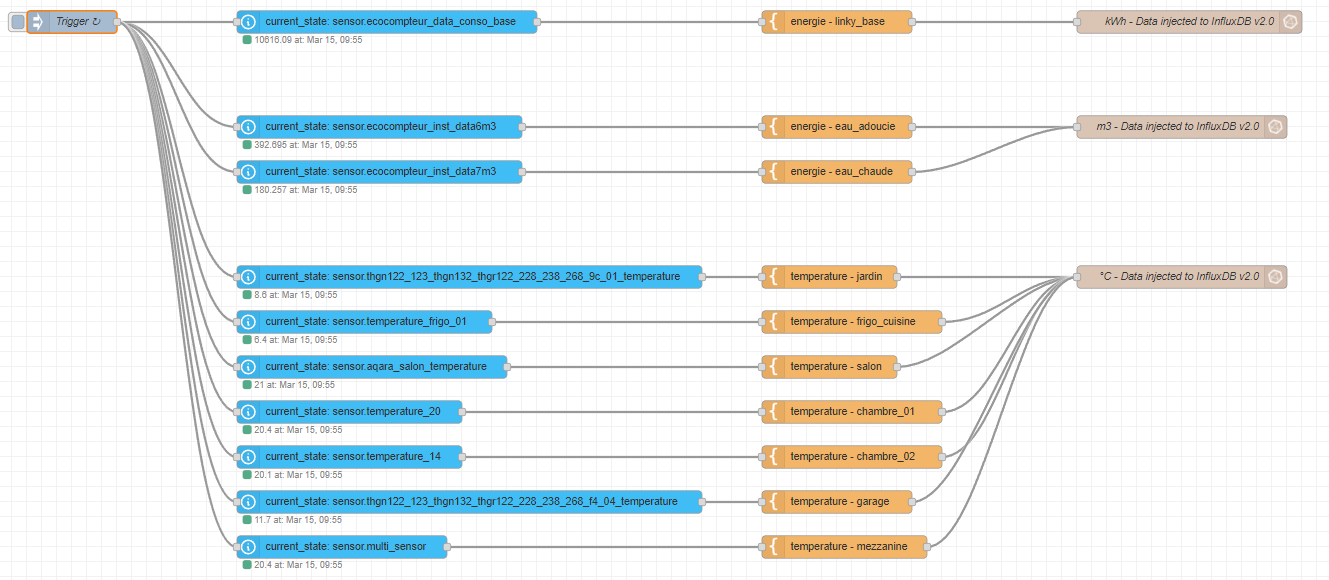
STEP 01 : Je déclenche le flow chaque minute comme ceci :
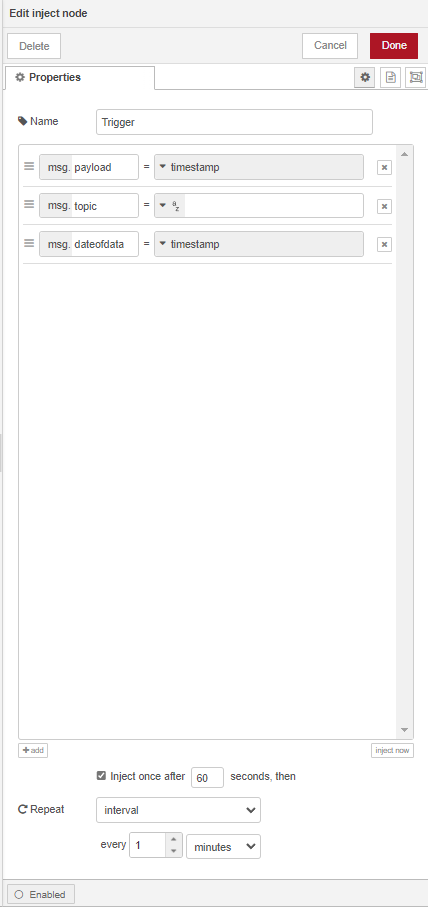
STEP 02 : Je lis les données provenant de HA comme ceci :
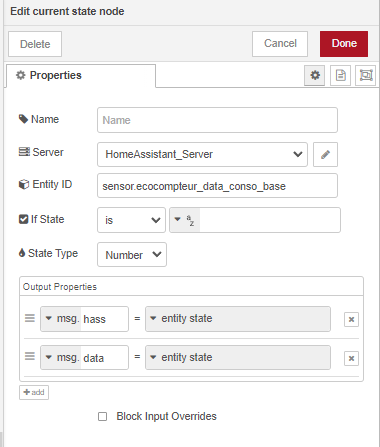
Avec pour définition du serveur HA ceci :
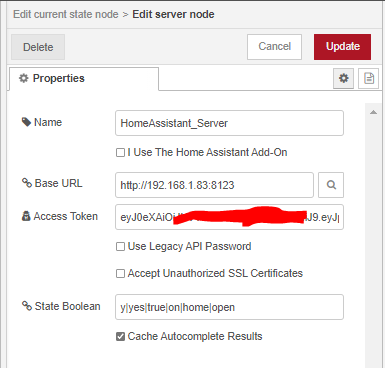
STEP 03 : J’ordonne mes données comme ceci :
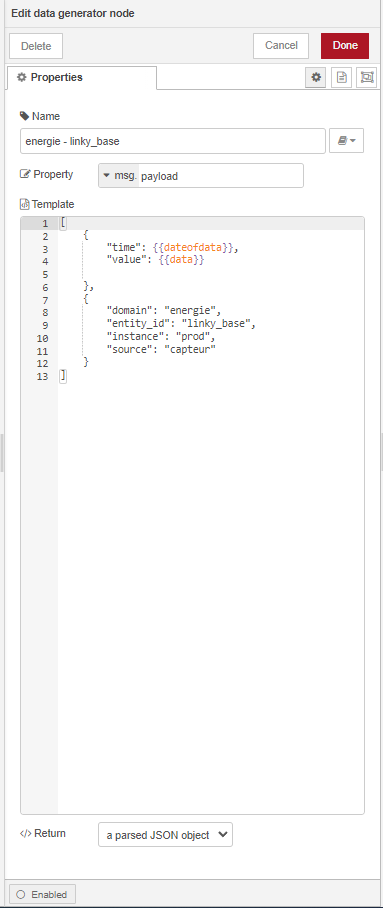
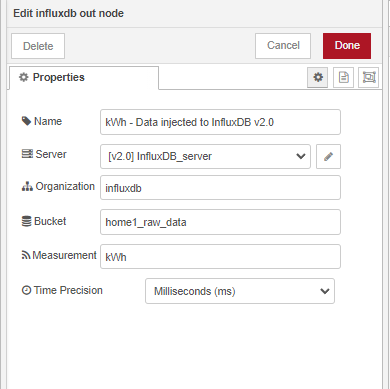
STEP 04 : J’injecte les données dans InfluxDB comme ceci :
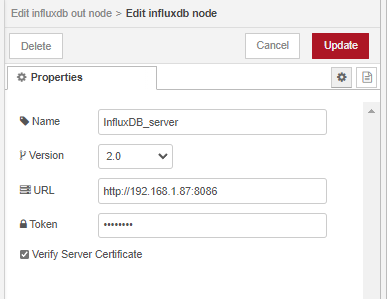
Avec pour définition du serveur InfluxBD ceci :
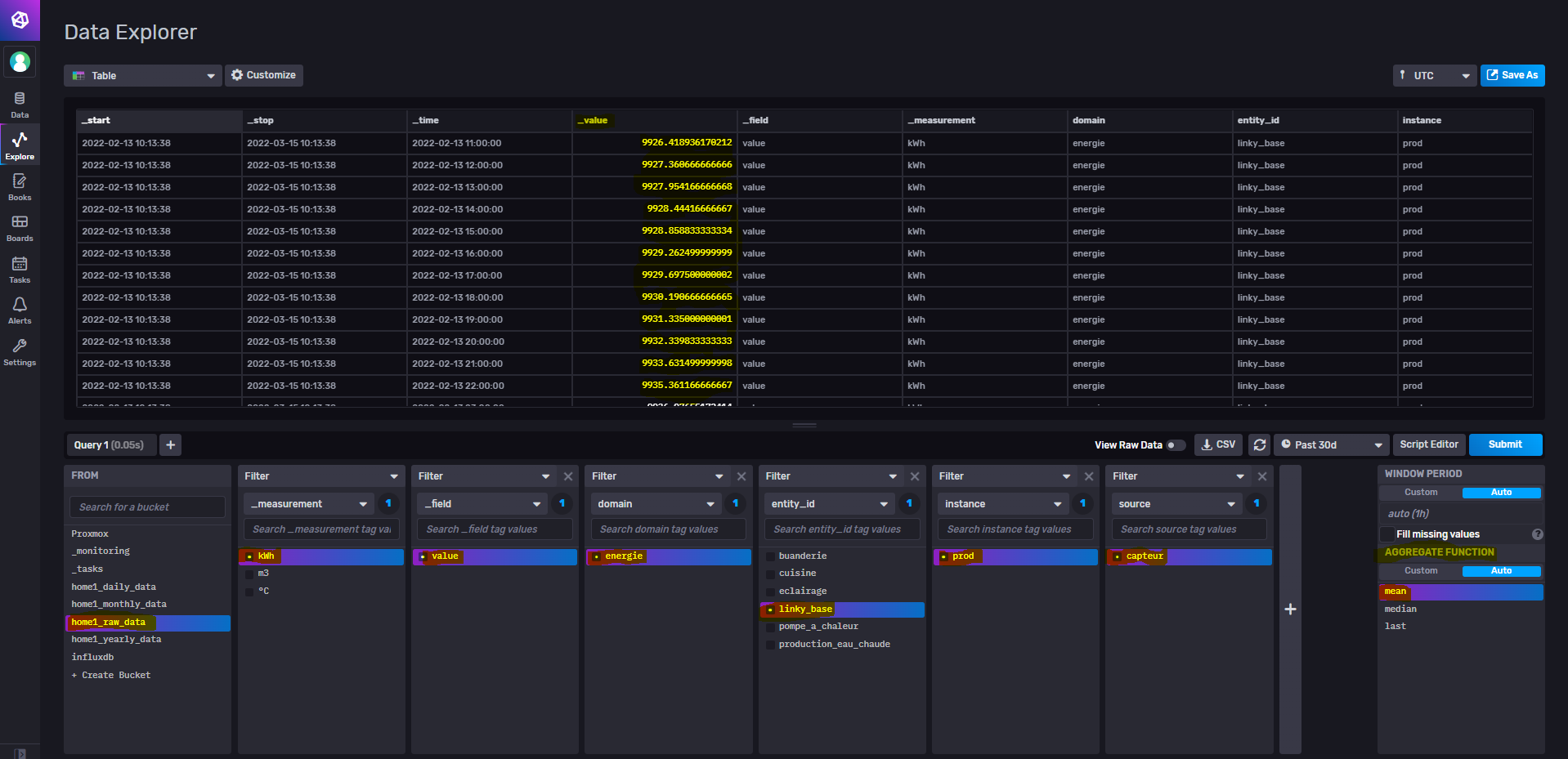
Ce qui donne dans InfluxDB :
=> Attention à l’affichage dans InfluxDB, car par défaut cela affiche une moyenne (agregate function)
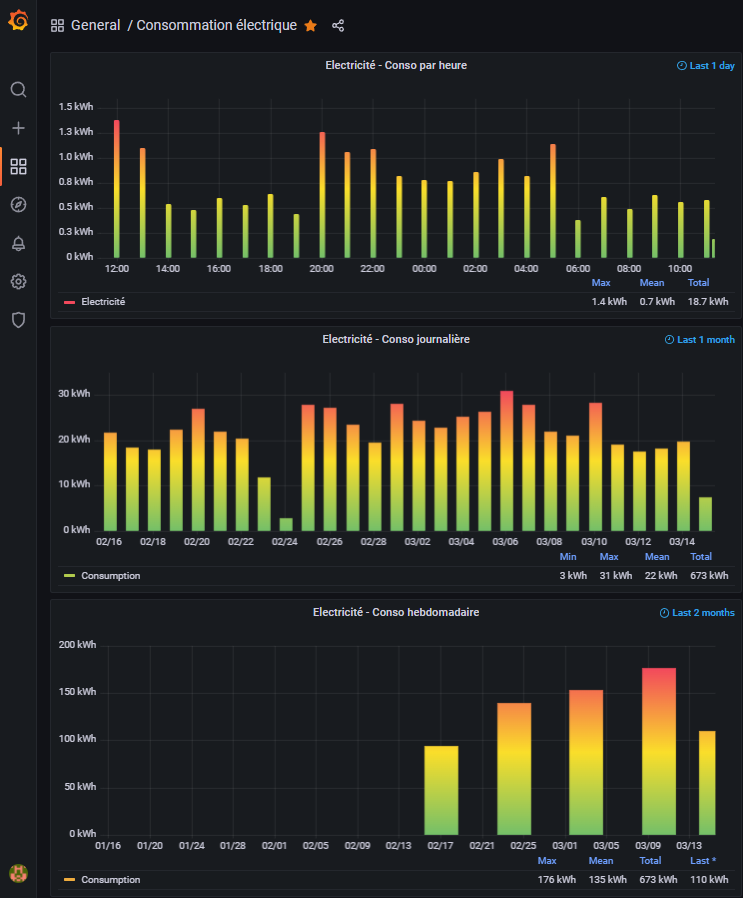
STEP 05 : Je lis les données InfluxDB sous Grafana ce qui me permet d’obtenir ceci :
-
Avec ce type de requête :
from(bucket: "home1_raw_data")
|> range(start: -1d)
|> filter(fn: (r) => r["_measurement"] == "kWh")
|> filter(fn: (r) => r["entity_id"] == "linky_base")
|> filter(fn: (r) => r["_field"] == "value")
|> filter(fn: (r) => r["domain"] == "energie")
|> filter(fn: (r) => r["instance"] == "prod")
|> filter(fn: (r) => r["source"] == "capteur")
|> drop(columns: ["domain", "instance", "source", "_start","_stop", "_field", "_measurement"])
|> aggregateWindow(every: 1h, fn: spread, createEmpty: false)
|> group()
|> pivot(rowKey:["_time"], columnKey: ["entity_id"], valueColumn: "_value")