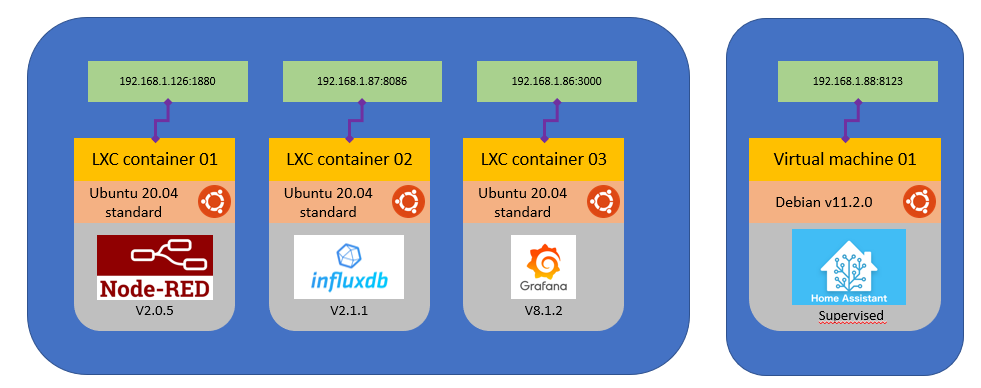
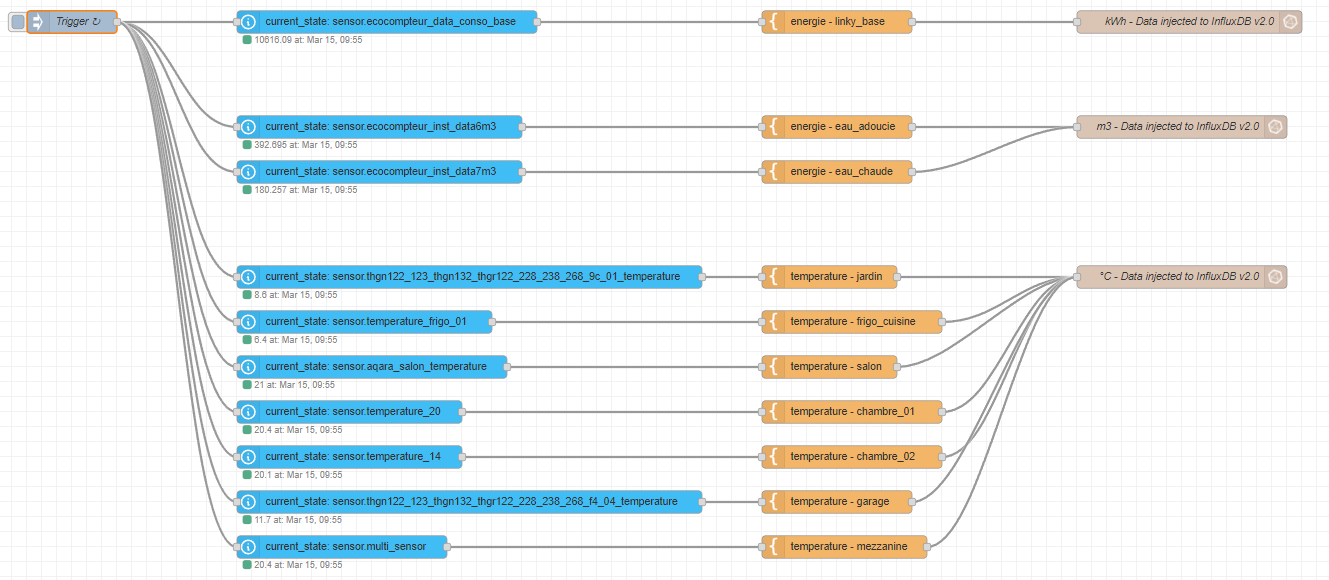
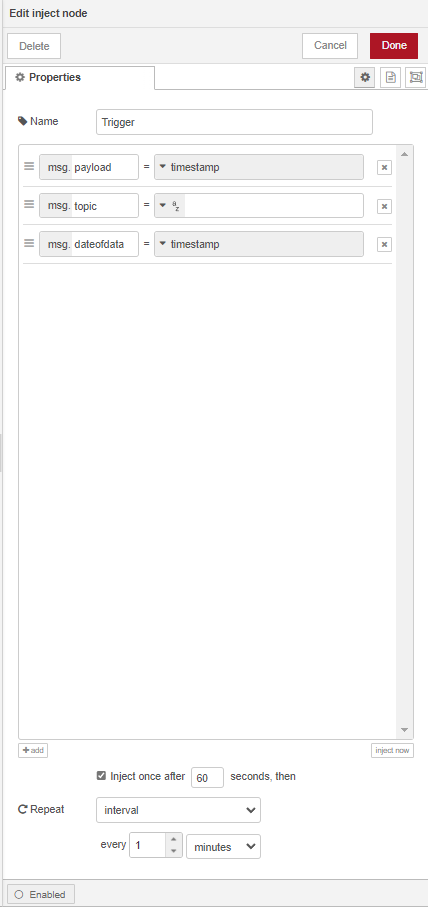
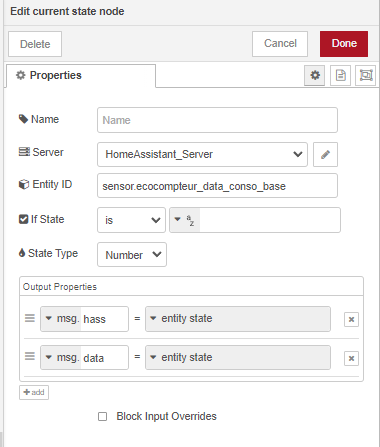
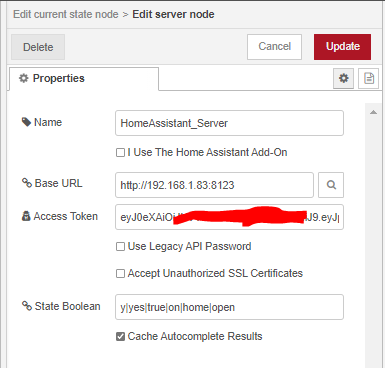
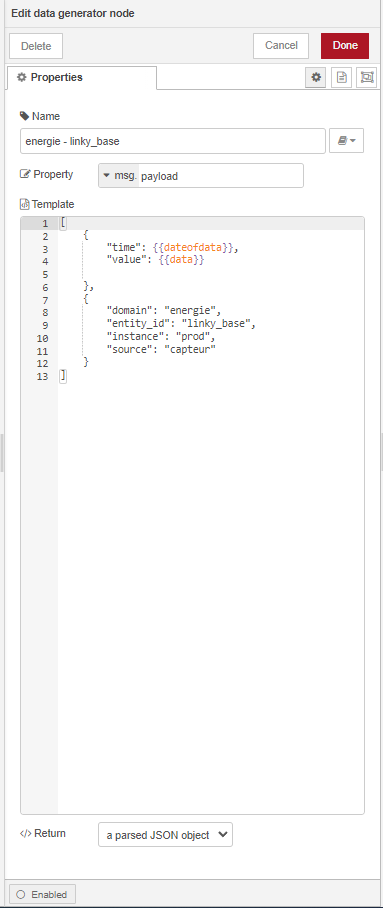
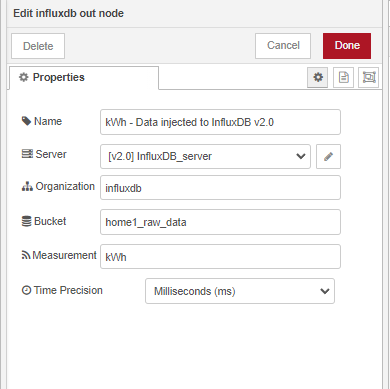
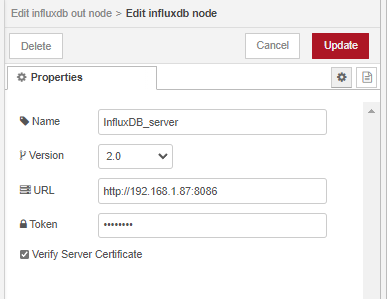
Salut à tous !
Suite à la demande de @Galadan, je vous partage mes tasks sur InfluxDB.
Je tiens à dire que je ne suis absolument pas informaticien donc il est fort probable que le code ne soit pas optimisé. Je suis bien évidemment preneur de toutes vos remarques constructives 
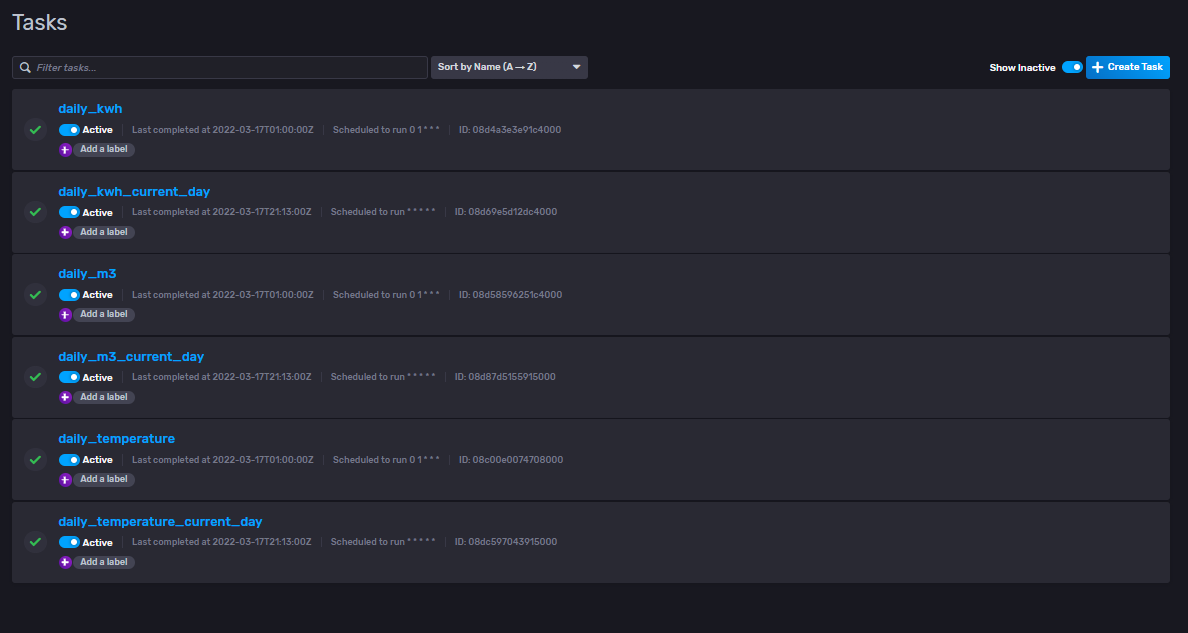
Voici donc la liste de mes tasks avec le code ci-dessous :
# Task « daily_kwh » :
import "date"
import "experimental"
import "math"
option task = {
name: "daily_kwh",
cron: "0 1 * * *",
}
TODAY = date.truncate(t: now(), unit: 1d)
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
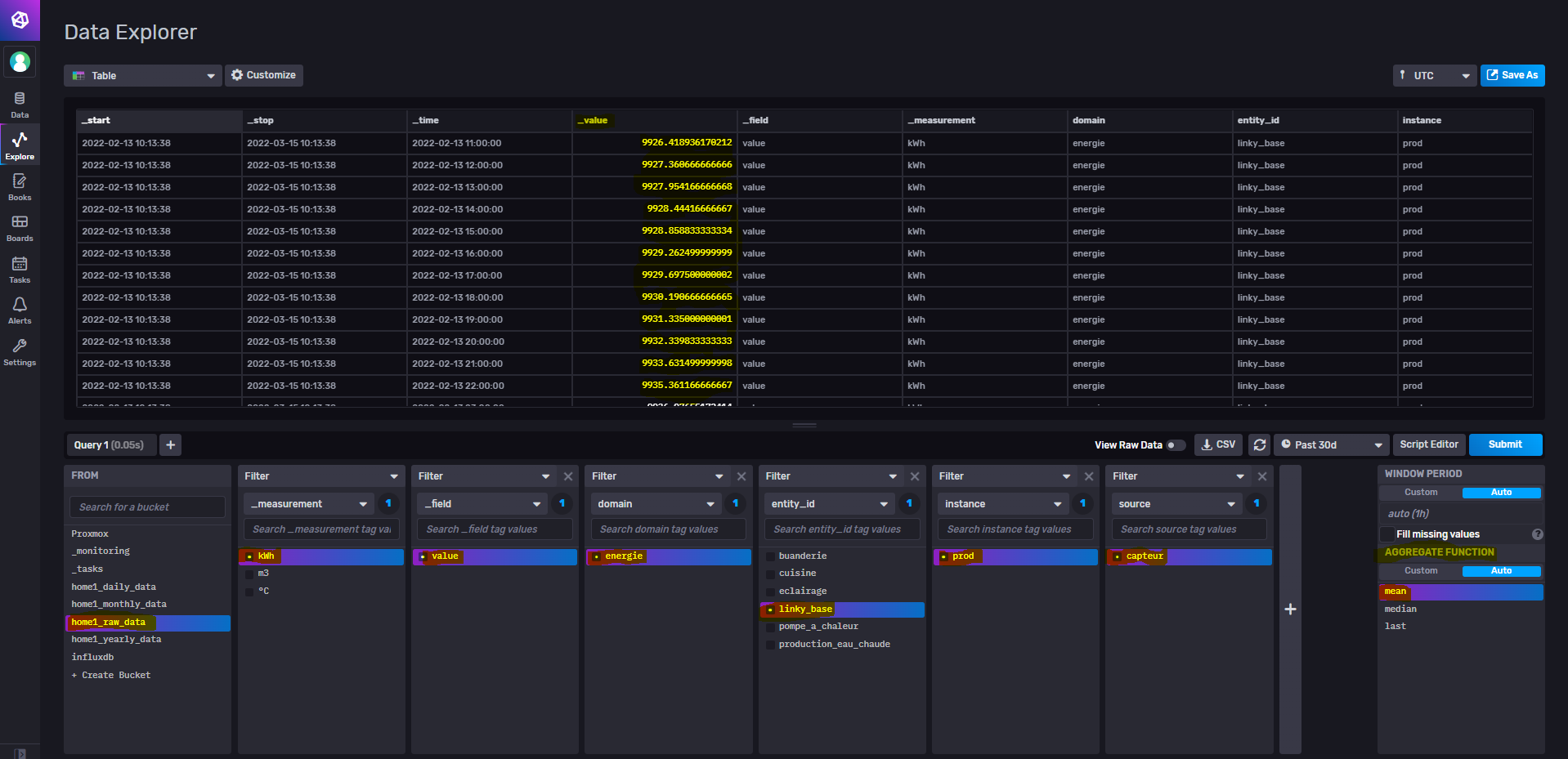
DATA1 = from(bucket: "home1_raw_data")
|> range(start: YESTERDAY, stop: TODAY)
|> filter(fn: (r) => r["_measurement"] == "kWh")
|> filter(fn: (r) => r["_field"] == "value")
DATA1
|> set(key: "source", value: "calculated")
|> reduce(
fn: (r, accumulator) => ({
min: if r._value < accumulator.min then r._value else accumulator.min,
max: if r._value > accumulator.max then r._value else accumulator.max,
_time: r._time,
}),
identity: {min: 10000000000.0, max: -10000000000.0, _time: YESTERDAY},
)
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> map(fn: (r) => ({r with _value: math.round(x: (r.max - r.min) * 100.0) / 100.0}))
|> map(fn: (r) => ({r with min: r.min}))
|> map(fn: (r) => ({r with min: r.max}))
|> to(bucket: "home1_daily_data")
# Task « daily_kwh_current_day » :
import "date"
import "experimental"
import "math"
option task = {name: "daily_kwh_current_day", cron: "* * * * *"}
TODAY = date.truncate(t: now(), unit: 1d)
DATA1 = from(bucket: "home1_raw_data")
|> range(start: TODAY, stop: now())
|> filter(fn: (r) => r["_measurement"] == "kWh")
|> filter(fn: (r) => r["_field"] == "value")
DATA1
|> set(key: "source", value: "calculated")
|> reduce(
fn: (r, accumulator) => ({
min: if r._value < accumulator.min then r._value else accumulator.min,
max: if r._value > accumulator.max then r._value else accumulator.max,
_time: r._time,
}),
identity: {min: 10000000000.0, max: -10000000000.0, _time: now()},
)
|> map(fn: (r) => ({r with _time: TODAY}))
|> map(fn: (r) => ({r with _value: math.round(x: (r.max - r.min) * 100.0) / 100.0}))
|> to(bucket: "home1_daily_data")
# Task « daily_m3 » :
import "date"
import "experimental"
import "math"
option task = {
name: "daily_m3",
cron: "0 1 * * *",
}
TODAY = date.truncate(t: now(), unit: 1d)
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
DATA = from(bucket: "home1_raw_data")
|> range(start: YESTERDAY, stop: TODAY)
|> filter(fn: (r) => r["_measurement"] == "m3")
|> filter(fn: (r) => r["_field"] == "value")
DATA
|> set(key: "source", value: "calculated")
|> reduce(
fn: (r, accumulator) => ({
min: if r._value < accumulator.min then r._value else accumulator.min,
max: if r._value > accumulator.max then r._value else accumulator.max,
_time: YESTERDAY,
}),
identity: {min: 10000000000.0, max: -10000000000.0, _time: YESTERDAY},
)
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> map(fn: (r) => ({r with _value: math.round(x: (r.max - r.min) * 1000.0) / 1000.0}))
|> to(bucket: "home1_daily_data")
DATA
|> set(key: "source", value: "calculated")
|> reduce(
fn: (r, accumulator) => ({
min: if r._value < accumulator.min then r._value else accumulator.min,
max: if r._value > accumulator.max then r._value else accumulator.max,
_time: YESTERDAY,
}),
identity: {min: 10000000000.0, max: -10000000000.0, _time: YESTERDAY},
)
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> map(fn: (r) => ({r with _value: math.round(x: (r.max - r.min) * 1000.0) / 1000.0}))
|> pivot(rowKey: ["_time"], columnKey: ["entity_id"], valueColumn: "_value")
|> map(fn: (r) => ({r with _value: math.round(x: (r.eau_adoucie - r.eau_chaude) * 1000.0) / 1000.0}))
|> set(key: "entity_id", value: "eau_froide")
|> to(bucket: "home1_daily_data")
# Task « daily_m3_current_day » :
import "date"
import "experimental"
import "math"
option task = {name: "daily_m3_current_day", cron: "* * * * *"}
TODAY = date.truncate(t: now(), unit: 1d)
DATA = from(bucket: "home1_raw_data")
|> range(start: TODAY, stop: now())
|> filter(fn: (r) => r["_measurement"] == "m3")
|> filter(fn: (r) => r["_field"] == "value")
DATA
|> set(key: "source", value: "calculated")
|> reduce(
fn: (r, accumulator) => ({min: if r._value < accumulator.min then r._value else accumulator.min, max: if r._value > accumulator.max then r._value else accumulator.max, _time: TODAY}),
identity: {min: 10000000000.0, max: -10000000000.0, _time: TODAY},
)
|> map(fn: (r) => ({r with _time: TODAY}))
|> map(fn: (r) => ({r with _value: math.round(x: (r.max - r.min) * 1000.0) / 1000.0}))
|> to(bucket: "home1_daily_data")
DATA
|> set(key: "source", value: "calculated")
|> reduce(
fn: (r, accumulator) => ({min: if r._value < accumulator.min then r._value else accumulator.min, max: if r._value > accumulator.max then r._value else accumulator.max, _time: TODAY}),
identity: {min: 10000000000.0, max: -10000000000.0, _time: TODAY},
)
|> map(fn: (r) => ({r with _time: TODAY}))
|> map(fn: (r) => ({r with _value: math.round(x: (r.max - r.min) * 1000.0) / 1000.0}))
|> pivot(rowKey: ["_time"], columnKey: ["entity_id"], valueColumn: "_value")
|> map(fn: (r) => ({r with _value: math.round(x: (r.eau_adoucie - r.eau_chaude) * 1000.0) / 1000.0}))
|> set(key: "entity_id", value: "eau_froide")
|> to(bucket: "home1_daily_data")
# Task « daily_temperature » :
import "date"
import "experimental"
import "math"
option task = {name: "daily_temperature", cron: "0 1 * * *"}
TODAY = date.truncate(t: now(), unit: 1d)
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
DATA = from(bucket: "home1_raw_data")
|> range(start: YESTERDAY, stop: TODAY)
|> filter(fn: (r) => r["_measurement"] == "°C")
|> filter(fn: (r) => r["_field"] == "value")
DATA
|> mean()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "mean")
|> set(key: "source", value: "calculated")
|> map(fn: (r) => ({r with _value: math.round(x: r._value * 10.0) / 10.0}))
|> to(bucket: "home1_daily_data")
DATA
|> min()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "min")
|> set(key: "source", value: "calculated")
|> to(bucket: "home1_daily_data")
DATA
|> max()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "max")
|> set(key: "source", value: "calculated")
|> to(bucket: "home1_daily_data")
# Task « daily_temperature_current_day » :
import "date"
import "experimental"
import "math"
option task = {name: "daily_temperature_current_day", cron: "* * * * *"}
TODAY = date.truncate(t: now(), unit: 1d)
DATA = from(bucket: "home1_raw_data")
|> range(start: TODAY, stop: now())
|> filter(fn: (r) => r["_measurement"] == "°C")
|> filter(fn: (r) => r["_field"] == "value")
DATA
|> mean()
|> map(fn: (r) => ({r with _time: TODAY}))
|> set(key: "statistics", value: "mean")
|> set(key: "source", value: "calculated")
|> map(fn: (r) => ({r with _value: math.round(x: r._value * 10.0) / 10.0}))
|> to(bucket: "home1_daily_data")
DATA
|> min()
|> map(fn: (r) => ({r with _time: TODAY}))
|> set(key: "statistics", value: "min")
|> set(key: "source", value: "calculated")
|> to(bucket: "home1_daily_data")
DATA
|> max()
|> map(fn: (r) => ({r with _time: TODAY}))
|> set(key: "statistics", value: "max")
|> set(key: "source", value: "calculated")
|> to(bucket: "home1_daily_data")