*En espérant poster au bon endroit, je n’ai pas trouvé chaussure à mon pied via mes différentes recherche (surement pas les bon termes). Ne pas hesiter à le déplacer si besoin. Voilà, je constate que je change régulièrement de système domotique (Jeedom, Domoticz, HA) et j’en ai marre de perdre mon historique donc j’aimerais sauvegarder hors de Home Assistant les valeurs des différents capteurs jugés important à mes yeux (températures, conso élec, état de ma ligne internet, pompe à chaleur, … ). Ceci afin de prévenir le futur car on ne sait pas ce que deviendra HA chez moi même s’il a aujourd’hui un bel avenir.
Mon idée de base était de créer une base de données MySQL sur un second raspberry. Restait ensuite à exploiter ses données via un outil de visualisation.
Salut @Guillaume_B,
Effectivement j’avais vu Influxdb et Grafana, j’ai d’ailleur mis en place une manip sur un pi 3 chez ma belle mere (température CPU). J’ai installé ceci via les add-ons de home assistant et je n’ai pas vraiment aimé le fonctionnement, je ne veux pas passer par les add-ons.
Comment ton system s’articule t’il ?
As-tu un rapide petit schéma pour comprendre comment HA communique avec influx, où les éléments son physiquement installé et qui écrit/lit depuis/vers qui.
Je me suis certainement mal exprimé et je ne veux surtout pas critiquer HA que j’adore, j’ai abandonné les autres système pour lui d’ailleurs !
Ce que je veux dire c’est que je souhaite un système indépendant de home assistant. Externaliser comme toi et @Guillaume_B me le suggère est je pense la bonne solution.
Pour être plus précis dans mon besoin, j’aimerai retrouver des choses assez simple avec surtout une base de données légère car mon premier home assistant avait une base de données énormes, plusieurs giga en quelques semaines ce qui n’est pas acceptable pour moi.
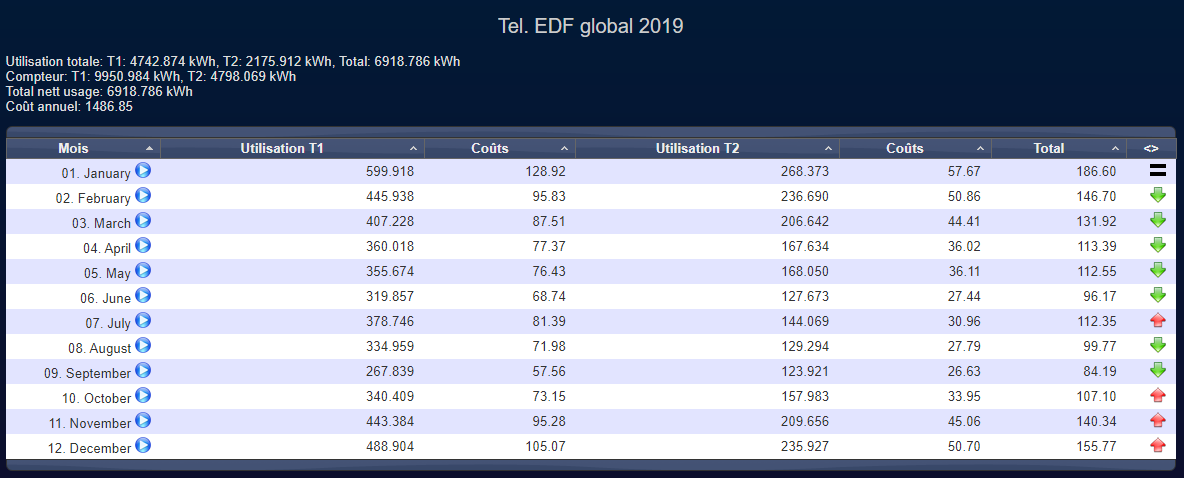
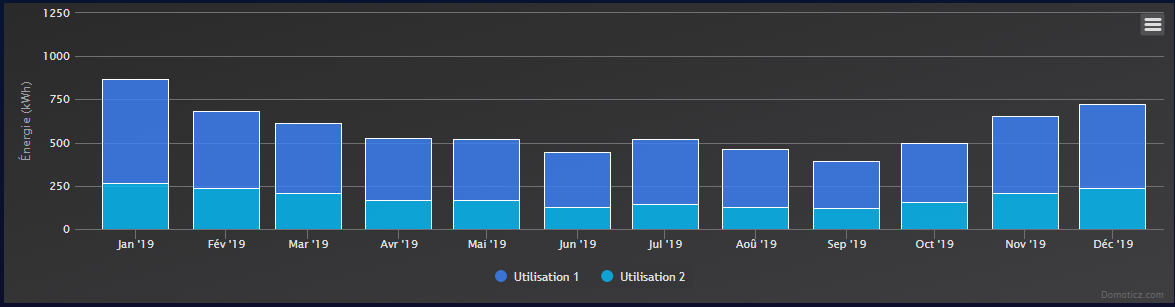
Pour exemple, la base de données de mon Domoticz pèse 4,6Mo pour 8 années d’historique (arrêté en janvier cette année) avec pourtant une centaine d’éléments dedans.
Merci à vous pour vos liens, je vais y regarder cependant si vous avez d’autres éléments je suis preneur !
J’ai installé Grafana sur la même machine que InfluxDB.
Après, oui la base de données est alimentée par Home Assistant et le noms des mesures est donc celui de HA. Si tu veux t’affranchir de ce nom et structurer ta base de données selon tes envies, tu peux passer par Node-RED pour aller lire tes sensors dans Home Assistant et les envoyer dans ta base de données avec le nom que tu veux. Je fais également cette manipulation pour un autre projet et ça fonctionne super bien.
Je suis sur smartphone…si tu veux plus de précisions, demande.
Merci @Guillaume_B,
C’est exactement ce dont j’ai besoin.
Du coup je vais me pencher plus attentivement sur l’ensemble InfluxDB + Grafana sur un second raspberry dédié avec docker compose. Je renommerai effectivement les données avec Nodered avant injection dans InfluxDB afin de garder la main pour le futur.
Je posterai içi un exemple une fois ma solution fonctionelle si cela est pertinent pour vous.
Tu n’es pas obligé de passer par Docker. J’ai installé cette solution directement sur Debian. Ça fait une couche en moins.
Attention à l’installation d’InfluxDB, il y a la version 2.0 qui est sortie. Elle amène beaucoup de changement. Personnellement je suis resté sur version 1.8
A l’occasion, je vais essayer de t’envoyer la fonction que j’utilise pour mettre en forme les données dans Node-RED avant l’insertion dans la DB.
Je vais me pencher dessus mais je pense que je partirai sur la dernière version si node-red est compatible avec. Cela m’évitera une migration
Pensez-vous qu’un raspberry pi 3 B+ soit suffisant pour au minimum faire un test ? Car j’ai prévu à Noël prochain d’investir dans un NUC donc je migrerai après.
C’est sur, mais docker est quand même préconisé pour les débutant.
Le simple fait de tout retrouver dans un seul et unique répertoire, le synchroniser sur un nas pour sauvegarde et se dire que si demain on change de machine, on a rien a faire a part reprendre son container et sa configuration (docker-compose aide la aussi).
Je suis d’accord pour docker car je veux être indépendant du hardware pour facilement évoluer ou simplement en cas d’un crash matériel.
Concernant HA je crée des Snapshots que je synchronise sur mon NAS chaque nuit. Trop eu de mauvaise surprise ! Donc je pense que j’aimerai faire la même chose avec influxDB et Grafana.
@Guillaume_B, @Clemalex,
Au final j’ai mis en place une machine de test avec Proxmox.
J’ai mis 2 container LXC Ubuntu 21.04 pour respectivement Grafana et InfluxDB. J’ai aussi mis une machine virtuelle avec Home Assistant OS afin de faire fonctionner tous ceci ensemble et apprendre à gérer les backup correctement.
Sinon, sans passer par Influx, tu peux également déporter ton recorder en dehors de ta machine HA.
Dans HA, on peut utiliser « MariaDB » comme recorder (via l’addon) qui install le gestionnaire de DB dans un container (dans le cas de HAOS). Ensuite il faut ajouter :
J’avais effectivement vu que ceci était faisable mais cela ne convient pas à mon besoin. Je souhaite stocker des années et des années d’historique.
Ceci concernant la partie recorder, d’après ce que j’ai lu ceci n’est pas fait pour historiser sur du long terme. Dans mon cas 7 jours est suffisant concernant l’historique HA. Ceci pour avoir des temps de chargement des graphiques acceptable.
J’effectue actuellement des tests sur mon proxmox, la manip en cours :
1x Virtual Machine avec HomeAssistant OS
1x container LXC avec UBUNTU 21.04 & NodeRed
1x container LXC avec UBUNTU 21.04 & InfluxDB v2.0
1x container LXC avec UBUNTU 21.04 & Grafana
Chaque élément est indépendamment sauvegardé. Ceci de façon régulière sur un NAS de façon automatique. Pour le moment j’arrive à récupérer les données de HA dans Nodered et à l’envoyer dans InfluxDB v2.0 (et non pas v1.8 afin de ne pas me taper une migration dans peu de temps).
Il me reste maintenant à utiliser les données InfluxDB dans Grafana.
Viendra ensuite le nettoyage quotidien de la base de données pour ne garder que les MIN / MAX / MOYENNE par jour pour l’historique de plus de 7 jours. Ceci afin de limiter la taille de la base de données sur le long terme.
Effectivement, la sauvegarde sur le long terme est un peu différente et l’utilisation d’influx est plus appropriée. J’y passerai certainement très prochainement après l’installation du monitorage des consommations (je reçu hier ma commande d’un shelly 3em pour cela).
Bon j’arrive maintenant à intégrer des anciennes données en forçant le timestamp dans nodered du coup la bonne nouvelle c’est que je vais pouvoir intégrer mes anciennes data et donc ne pas perdre mon historique. => 8 années quand meme !
Je vais cependant regarder si cela ne serait pas plus simple (ou plus rapide) d’intégrer un fichier CSV.
Mon idée étant :
Exporter mes anciennes données issuent de la base mySQL de DOMOTICZ vers un fichier CSV
Modification du CSV pour correspondre à 100% à l’architecture de ma nouvelle database InfluxDB
Comme j’ai dit à Pulpy hier, j’ai malheureusement du mettre un peu en pause le sujet (découverte des Cryptomonnaie et du potentiel de la technologie blockchain).
Je partagerai bien évidemment ma solution, c’est le but de la communauté, obtenir de l’aide mais également en fournir (quand on peut)