Je pense que je vais devoir ouvrir un poste pour éviter de polluer celui-ci à l’avenir mais il faut me comprendre, j’aime partager mes avancées sur ce forum chaleureux ![]()
Coté InfluxDB :
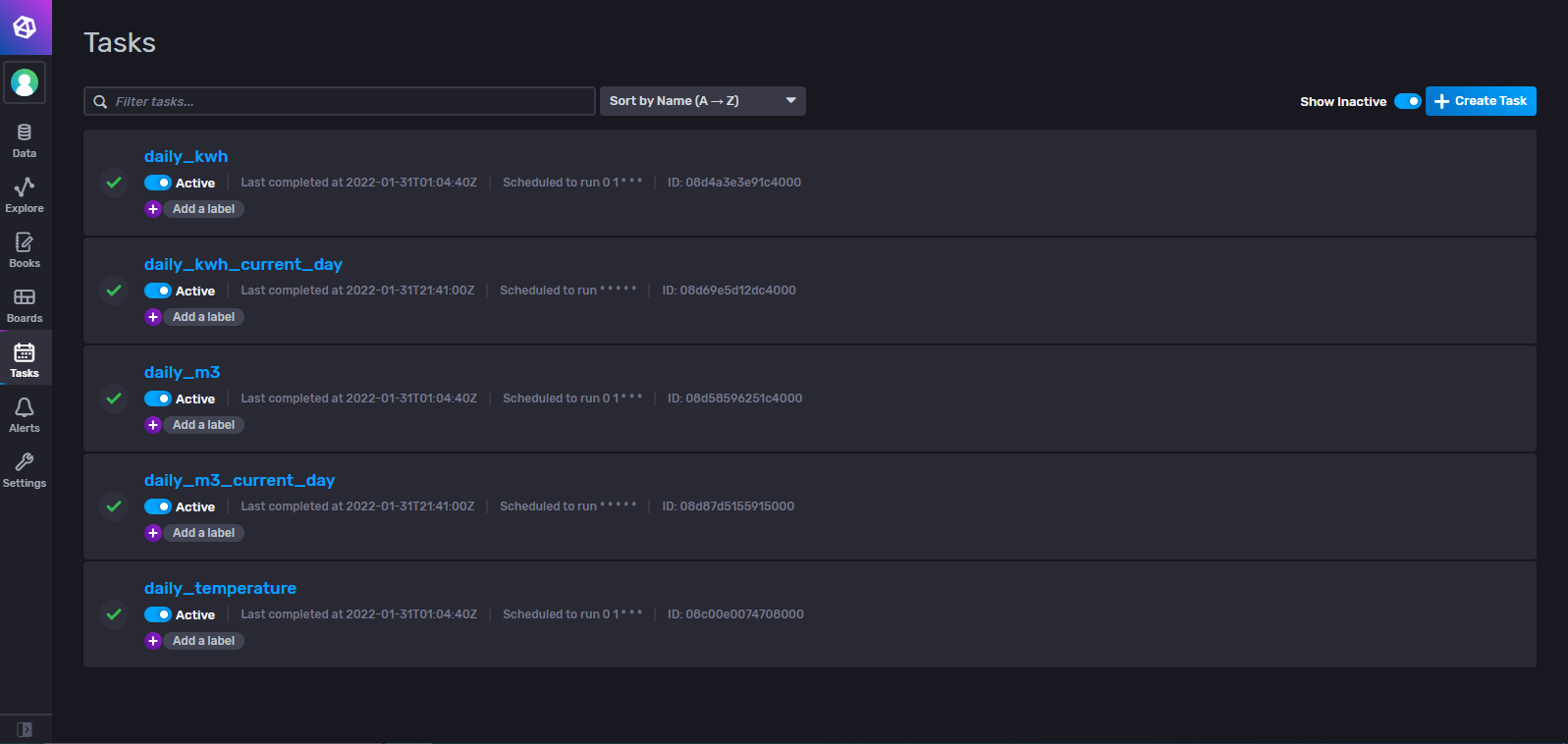
- J’ai mis de l’ordre dans mes tasks :
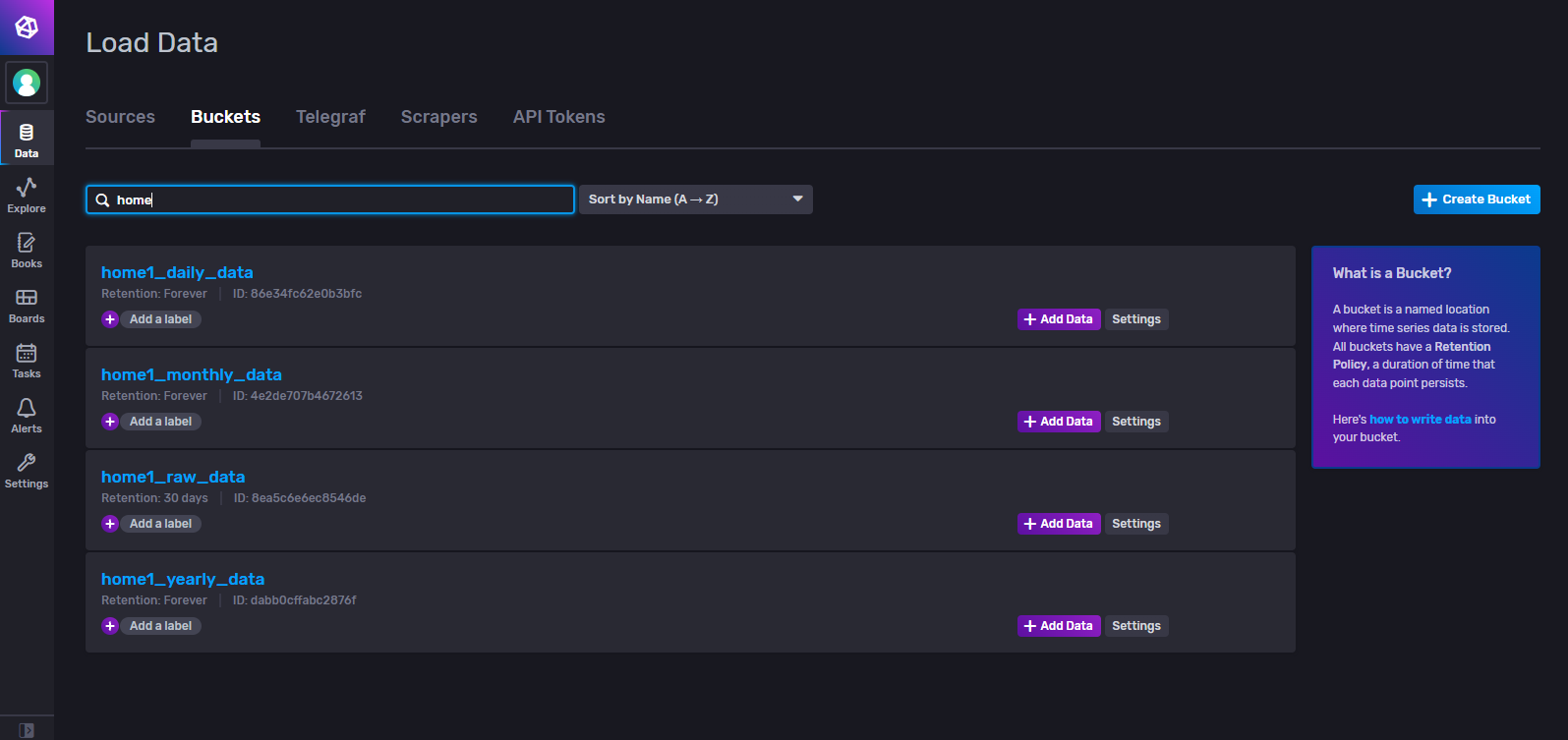
- J’ai mis de l’ordre dans mes buckets :
Coté grafana :
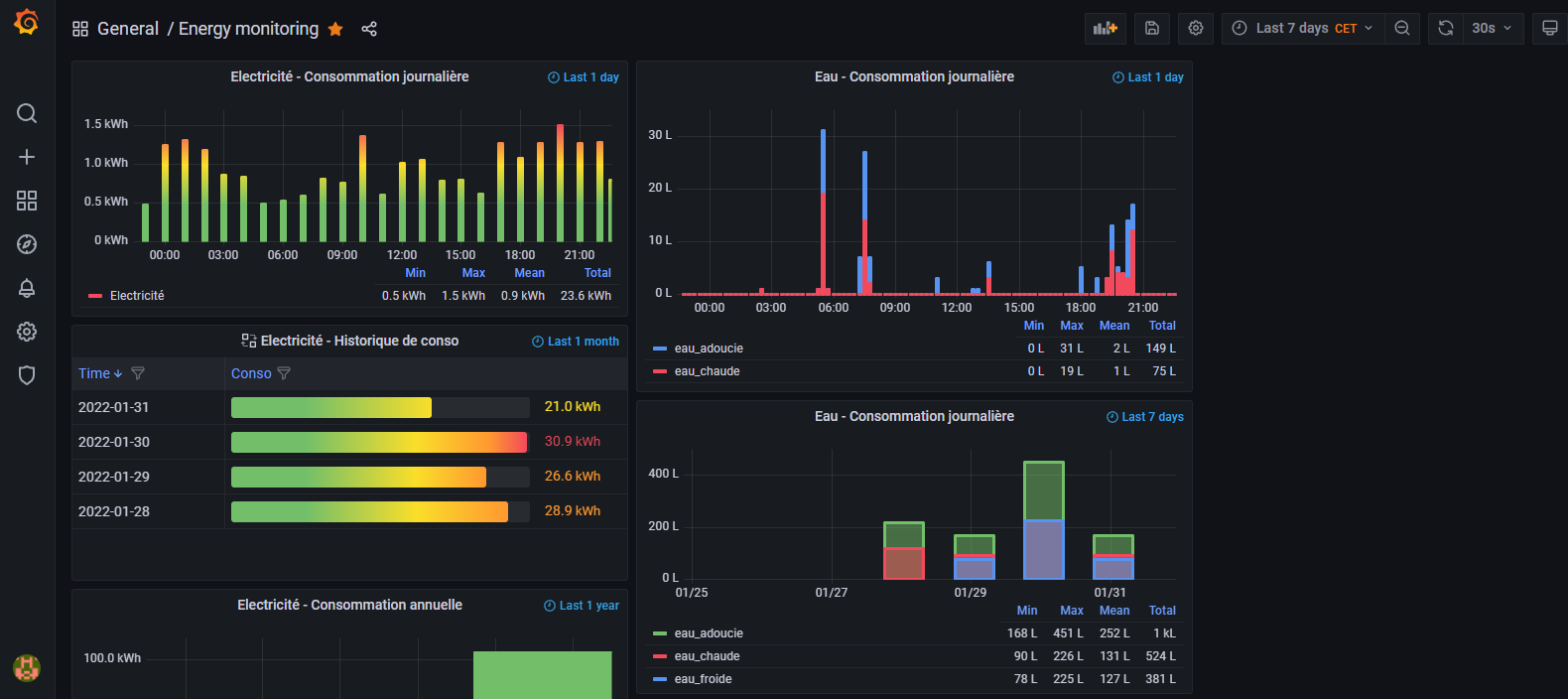
- Je commence à le prendre en main, voici mon premier dashboard :
Pour conclure :
J’ai organisé mes buckets en fonction de la tache que je leur associe :
- Bucket n°1 => Données brutes, un enregistrement par minute, les données sont effacées au bout de 30jours
- Bucket n°2 => Données traitées, un enregistrement par jour contenant les statistiques (min, max, moyenne, conso, …), stockage moyen terme
- Bucket n°3 => Données traitées, un enregistrement par mois contenant les statistiques (min, max, moyenne, conso, …), stockage très long terme
- Bucket n°4 => Données traitées, un enregistrement par année contenant les statistiques (min, max, moyenne, conso, …), stockage très long terme