Hello !
Je vous propose de compléter le très bon tuto disponible ici :
Comme ce sujet vient en complément, je vous suggère donc de commencer par suivre le tuto en question avant de passer ici ![]()
![]()
Quelques pré-requis :
- Suivre le tuto d’install influxdb.
- Connaître Nodered
![]()
Je vais faire plusieurs assomptions pour aller au plus simple et généraliste :
- Vous utilisez influxdb v1.x et non une 2.x !!!
- Vous avez utilisé l’addon nodered et l’addon influxdb (je ne recommande pas forcément ce choix pour influxdb, j’en parlerai à la fin)
- Vous utilisez la retention policy autogen (si vous n’avez pas compris, c’est le cas, sinon vous sauriez de quoi je parle)
- Vous aller utiliser la même database influx pour HA et Nodered
![]()
Petit tour de ce que je vais détailler :
- Envoyer des données dans influxDB depuis Nodered
- Récupérer des données de influxDB dans Home Assistant
- Exemple de requête sympa pour des min/max d’entités
- Petite digression sur l’addon influxdb
- Vous avez des questions / des suggestions ? Demandez / Proposez !
Envoyer des données de Nodered vers InfluxDB
-
Pourquoi ?
Parce que tout ne s’intègre pas dans Home Assistant directement. (oui oui !). Soit par choix, soit parce que tout simplement ce n’est pas possible. -
Comment ?
Avec le paranormal !
Non ? OK, avec le noeudinfluxdb out(wow !)
La pratique
Pour envoyer des informations de Nodered vers influxDB on va donc utiliser le noeud influxdb out il est déjà présent si vous utilisez l’addon nodered de Home Assistant.
![]()
La configuration de ce noeud est…sommaire ![]()
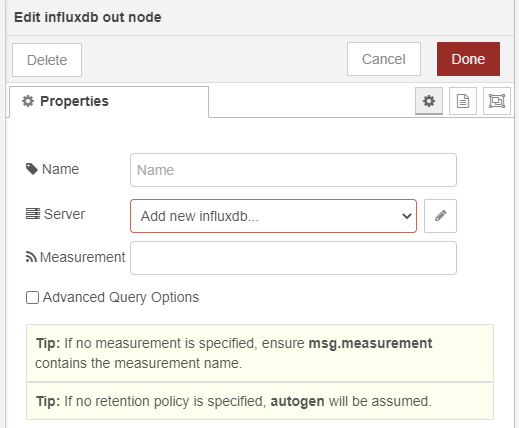
La première étape, configurer un serveur influxdb pour tous vos nœuds influxdb de nodered (à la manière de mqtt par exemple) en insérant un noeud influxdb out et en cliquant sur le petit crayon à côté de la case Server (voir screenshot précédent). Comme ceci :
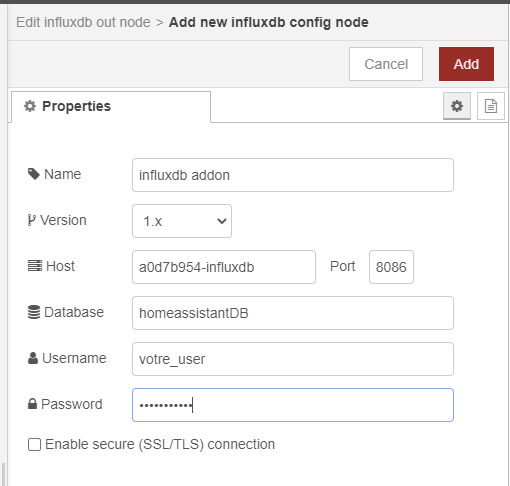
Remplissez les champs username et password avec les valeurs que vous avez définies
dans l’addon influxdb.
On va donc se servir de la même database que HA. Soyez donc malins sur les noms de ce que vous allez y envoyer pour ne pas écraser/mélanger des données !
(Vous pouvez aussi choisir de créer une database influx dédiée à l’envoi des infos via nodered, je vous renvoie pour ça au tuto cité au début de cet article ! Pensez à adapter ce tuto si c’est le cas…)
Une fois tout bien configuré appuyez sur Add ! Et Deploy pour enregister !
Ensuite la configuration du nœud influxdb out…
Donc comme vu avant, pas grand chose au final. La majeure partie est en fait, faite en amont du nœud et les propriétés sont récupérées dans le msg.
Il faut donc, mettre en forme le msg avant de le passer au noeud influxdb out.
Dans le msg il vous faudra au minimum la valeur (nombre ou chaine de caractères) dans le payload (msg.payload).
Si vous ne faites que ça, la valeur msg.payload sera intégrée au field value sur le measurement défini dans la configuration du nœud influxdb out.
Rien capté ? OK exemple !
On a un nœud inject comme ça :
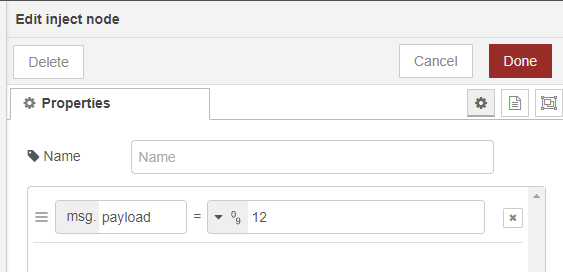
relié à un nœud influxdb out comme ça :
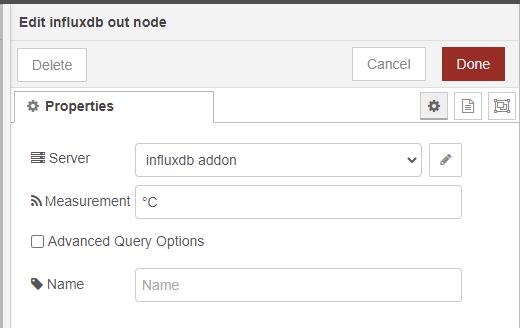
Soit :

(ce flow est énorme, Eminem est jaloux ! #jokeDePapa)
Quand on va appuyer sur le inject, la valeur 12 sera stockée dans un measurement nommé °C dans le field appelé value.
Utiliser le field value, par défaut c’est une bonne idée, car au final on va souvent stocker un truc qui est une valeur. Donc dans la majorité des cas vous utiliserez ce field.
Pour ce qui est du measurement c’est en fait l’unité de mesure de la valeur que vous allez stocker !
Influxdb regroupe les unités, c’est un classement comme un autre ![]()
Bon OK, c’est cool mais si j’ai plein de trucs qui mesurent des °C et que je stocke dans value, tout va se mélanger ???
Oui… ![]()
C’est là que vous avez besoin des tags d’influx !
Et ces tags, ben faut les définir dans le msg.payload encore une fois !
On y retourne par l’exemple :
On change notre noeud inject comme ça :
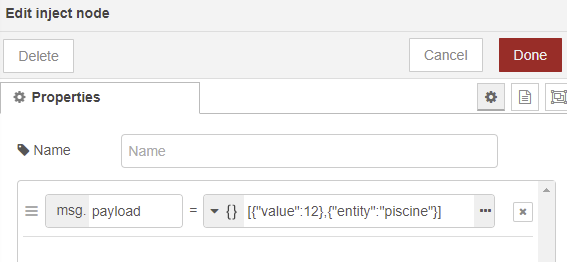
On injecte donc du json, un array, avec en premier, le field, en second le tag.
On ne touche pas au noeud influxdb out.
Quand on va injecter ce json influxdb va stocker dans le
measurement °C la valeur 12 avec un tag qui s’appellera entity et qui aura pour valeur piscine.En effet, en plus de grouper les valeurs par unité, influxdb donne la possibilité de grouper par tags. Vous pouvez nommer vos tags comme vous le sentez et leur donner la valeur souhaitée aussi. Pour cet exemple je pars du principe que entity c’est pas mal raccord avec ce que fait HA.
Attention tout de même, si vous spécifiez un tag entity avec une valeur d’entité qui existe dans votre HA et qui est envoyée dans influxdb alors vous avez un risque de mélange de données !
Vous pouvez bien sûr spécifier plus d’un seul tag, par exemple :
[{"value":12},{"entity":"piscine","température":"eau"}]
Vous pourrez ainsi filtrer par le tag que vous préférez dans vos graphiques (ou sensors HA !).
Récupérer des données qui sont dans influxDB avec HA
Ben oui, on à la température d’eau de la piscine dans influxDB mais pas dans HA. C’est pas génial…
Du coup on peut créer un sensor, avec les valeurs extraites de influxdb !
Comment ? Ben on suit la documentation
Mais si j’arrêtai là ça ne serait plus un tuto…
Donc, c’est parti !
Pour récupérer cette valeur de température d’eau de piscine dans HA, on ajoute à sa config de sensors :
sensors:
platform: influxdb
host: a0d7b954-influxdb
database: homeassistantDB
username: !secret influxdb_user
password: !secret influxdb_password
queries:
- name: temperature_piscine
unit_of_measurement: °C
measurement: '"°C"'
where: '"entity" = ''piscine'''
field: value
Donc on va chercher le field nommé value où le tag entity vaut piscine dans le measurement °C
Tout ça va créer un sensor.temperature_piscine dans votre Home Assistant.
Je vous conseille TRÈS VIOLEMMENT d’exclure cette entité des entités transmises à influxDB. Sinon vous voyez le truc ? On récupère une valeur de influxdb dans HA qui l’envoie dans influxdb…pas super malin ![]()
Exemple de requête sympa pour du min/max
Admettons que vous envoyez les valeurs de vos entités HA dans influx. Moi je le fais. J’aime bien connaître la température mini et maxi dans les pièces pour la journée en cours.
Avec HA, y’a rien de pratique pour faire ça, on peut le faire mais sur les 24 heures passées par exemple, pas depuis le début de journée (en tout cas j’ai pas trouvé de truc simple). Et bien influxdb peut aider !
Voici une requête que j’utilise :
- name: min temp bureau
unit_of_measurement: °C
measurement: '"°C"'
group_function: min
where: '"entity_id" = ''bureau_temperature'' AND time >= {{(as_timestamp(now()) - (now().hour * 3600) - (now().minute * 60) - (now().second)) | round(0)}}s'
field: value
- name: max temp bureau
unit_of_measurement: °C
measurement: '"°C"'
group_function: max
where: '"entity_id" = ''bureau_temperature'' AND time >= {{(as_timestamp(now()) - (now().hour * 3600) - (now().minute * 60) - (now().second)) | round(0)}}s'
field: value
Ceci va créer 2 sensors. sensor.min_temp_bureau avec la valeur mini durant la journée en cours et max_temp_bureau pour la valeur maxi ![]()
Je vous laisse décortiquer, les parties les plus intéressantes sont group_function et where
Garder ses données longtemps
Oui, le but c’est bien de garder ses données le plus longtemps possible. Ce que HA ne doit pas faire (perso j’ai 3 jours sur HA pas plus).
Mais vous avez sûrement des capteurs qui ont des valeurs très changeantes, ce qui donne une montagne de données… Alors garder 1an de données précises OK mais au delà ? On a vraiment besoin de garder un relevé de température toutes les minutes ? ![]()
Du coup, vous pouvez mettre en place du downsampling (en français ça doit se dire « échantillonage » revu à la baisse ![]() )
)
Pour ça on à 2 étapes :
- créer une seconde retention policy
- créer une continuous query
Pour créer la seconde retention policy direction chronograph (l’interface web de l’addon influxdb) et le menu « InfluxDB Admin » (icone couronne )
)
Trouvez votre database sur laquelle vous voulez faire du downsampling et créez une nouvelle retention policy avec le bouton « add retention policy »
Donnez lui un nom, et mettez une durée de rétention (optionnel, si pas de durée alors rétention infinie !)
Personnellement, j’ai pour mes datas hassio opté pour 380 jours par défaut avec la précision maximale et 700 jours avec du downsampling. Au delà de 700 jours les données disparaissent !
Ensuite, il va falloir créer la continuous query qui va prendre vos données qui ont la précision maxi pour en faire des données « moyennées » sur un laps de temps.

J’explique avant d’aller plus loin. Imaginons un capteur hyper sensible remonte une valeur toutes les 30 secondes, et à chaque fois une valeur différente. Sur 5 minutes vous aurez donc 11 points. Avec le downsampling sur une période de 5 minutes on va prendre ces 11 points, faire la moyenne et créer un seul point avec cette valeur moyenne ! On divise juste par 11 la taille de la base de données quoi…
Donc la continuous query :
Toujours dans chronograf, direction le menu « explore ». Dans le champ ou vous pouvez taper une requête on va créer la continuous query.
Exemple avec une query nomée « hass_down » sur une database nomée « hassio », un downsampling sur 5 minutes dans une retention policy nomée « hassio_downsample » :
CREATE CONTINUOUS QUERY "hass_down" ON "hassio" BEGIN SELECT mean(*) INTO hassio."hassio_downsample" FROM hassio.autogen./.*/ GROUP BY time(5m), * END
Cette continuous query va prendre toutes les valeurs et les moyenner sur 5 minutes et les enregistrer dans la retention hass_downsample.
Attention, le field par défaut qui s’appelle « value » sera renommé en « mean_value », il faudra y penser une fois dans grafana pour afficher des valeurs !

Petite digression sur l’addon influxdb
C’est vrai que les addons sont pratiques, mais, ma vision des choses (et c’est absolument personnel !) c’est que domotique ≠ monitoring !
Influxdb, c’est quoi ? => UNE DATABASE ! Pas de la domotique.
Pourquoi mon soft domotique serait responsable de ma banque de données ?
Personnellement, mon influxdb tourne sur une VM dédiée aux datas. Sur cette VM :
- influxdb
- chronograf
- grafana
- postgresql
De plus, la configuration de ma base de données HA (j’utilise postgresql) est faite de façon à ce que seul les 3 derniers jours sont stockés. Pour les datas à long terme, c’est influxdb qui le fait.
Pourquoi ? Influxdb est FAIT pour ça, postgresql non, sqlite (la base par défaut HA) non plus…
Alors, oui les addons c’est sympa, mais à mon avis, certains ne devraient pas exister. Comme celui d’influxdb.
Enfin, pour enfoncer le clou. Petits retours d’expérience.
-
En ce temps là
 HA était en charge de ma télérelève EDF (via des sensors MQTT) et HA a été victime d’un bug, plus aucune data n’était envoyée à influxdb…Rien…
HA était en charge de ma télérelève EDF (via des sensors MQTT) et HA a été victime d’un bug, plus aucune data n’était envoyée à influxdb…Rien…
Du coup, mes valeurs, sorties de nodered, passées à MQTT, passées à HA et…ben rien, effacées au bout de 3 jours LOL.
Du coup, j’ai tout changé, mes datas de télérelève sont extraites par nodered, puis envoyées direct dans influxdb. Et HA, récupère quelques unes de ces valeurs pour les afficher sur lovelace. Mais il n’est pas en charge de transmettre quoi que ce soit. -
Je voulais monitorer mes noeuds proxmox. Et dans proxmox on peut indiquer un serveur influxdb pour aller y stocker les données. MAIS, chez proxmox ils ont décidé que les données sont envoyées en UDP et l’addon influxdb, ben il ne supporte pas l’UDP… J’ai été ouvrir un PR sur l’addon pour ajouter cette possibilité et la réponse à été : « Non merci ! »
Du coup je fais tourner MON influx A MOI ! Et je fais ce que je veux avec ! NA !
Questions ?
![]()