Autre point aussi, stocker tout en UTC me va bien pour les valeurs brutes mais pour le traitement des données avec le changement d’heure je m’interroge. Je me demande s’il n’y a pas un truc à faire avec ceci :
https://www.influxdata.com/blog/time-zones-in-flux/
Tu es certain de l’impact ?
1 min, 1 mean, 1 max par jour que ce soit 0h utc ou 0h utc+1 on s’en fiche un peu, ça reste 1 valeur par jour
L’impact je ne pense pas qu’il y en ai vraiment un, surtout pour la température, mais pour l’élec je sais pas car on crée un offset d’une heure donc pour une intégrale…
Dans tous les cas j’aimerai savoir comment faire car déjà je suis un peu maniac et en plus cela me fera une compétence de plus. ![]()
@Pulpy-Luke ,
As-tu trouvé une solution pour généraliser le script min/max/mean ?
En gros comment faire pour appliquer le script aux autres « entity_id » sans dupliquer le script autant de fois qu’il y a de capteurs ce qui deviendrait ingérable dans le temps.
J’ai crée un post à ce sujet :
https://community.influxdata.com/t/how-to-write-a-generic-task-for-all-table/23348
Pour l’instant non
J’ai dans l’idée de faire une requête pour faire la liste des entity_id… + une boucle de 3 fonctions (min/mean/max) par entity_id.
Mais je suis vraiment mauvais en base de données, pê des group_by à ajouter aussi
Comme ça: Use parameterized Flux queries | InfluxDB Cloud (TSM) Documentation
Apparemment il faut passer par l’API pour faire ça.
influxdb, c’est plutôt bien. Mais, je trouve ça très tordu comme approche. Là et en général…
Donc, tu gardes ta query du côté HA ou NR et avec les paramètre tu t’en sors.
Ca, c’est la théorie. Tu nous diras pour la pratique ![]()
Je suis toujours en influxdb 1.x avec le vieux langage de requête. Je les construis (péniblement) dans grafana… Avec flux c’est du sans filet. Comme j’ai peur du vide, je reste au bord.
1 « J'aime »
Il y a le créateur pour filer un coup de main à la construction c’est pas mal pour générer la bonne syntaxe
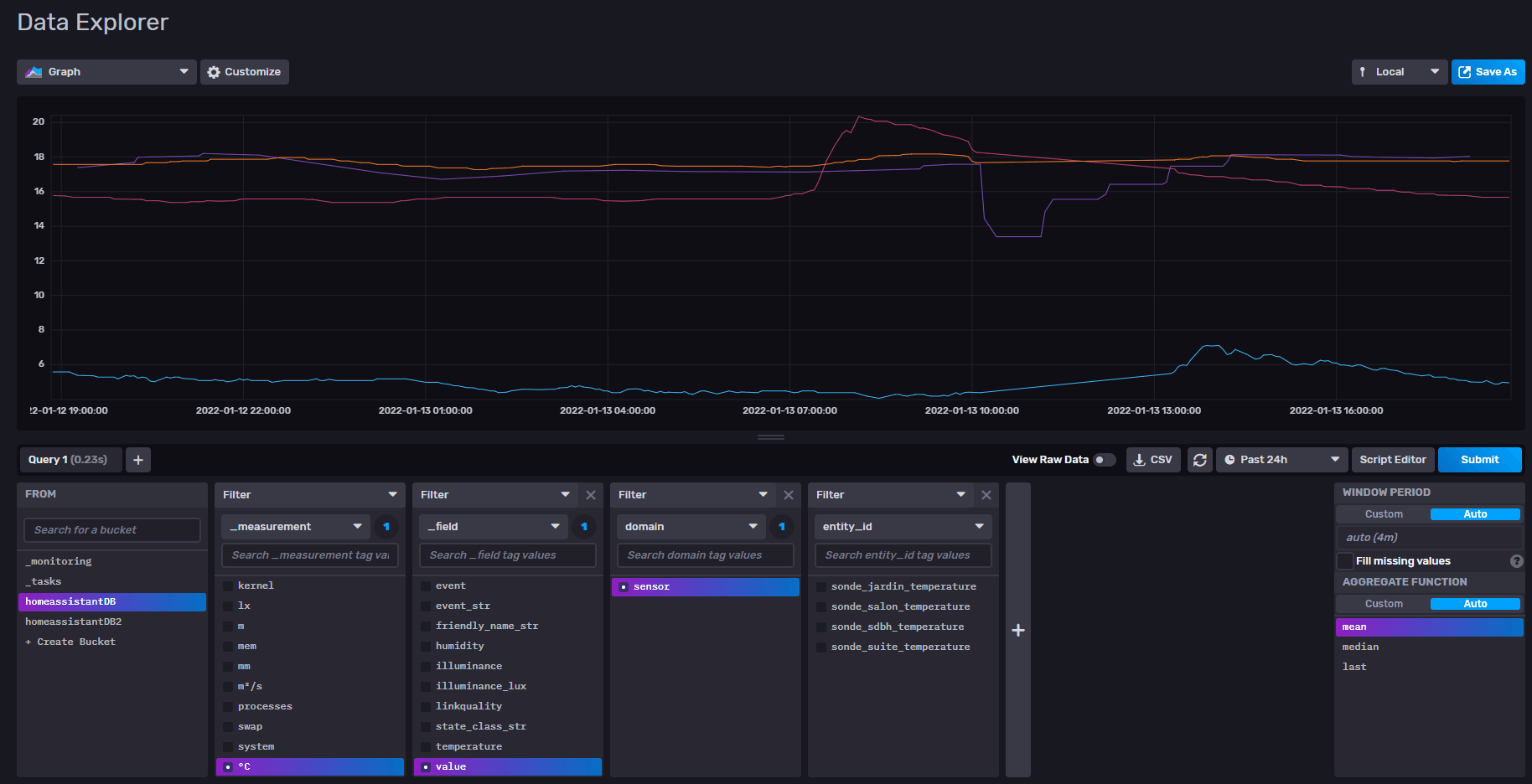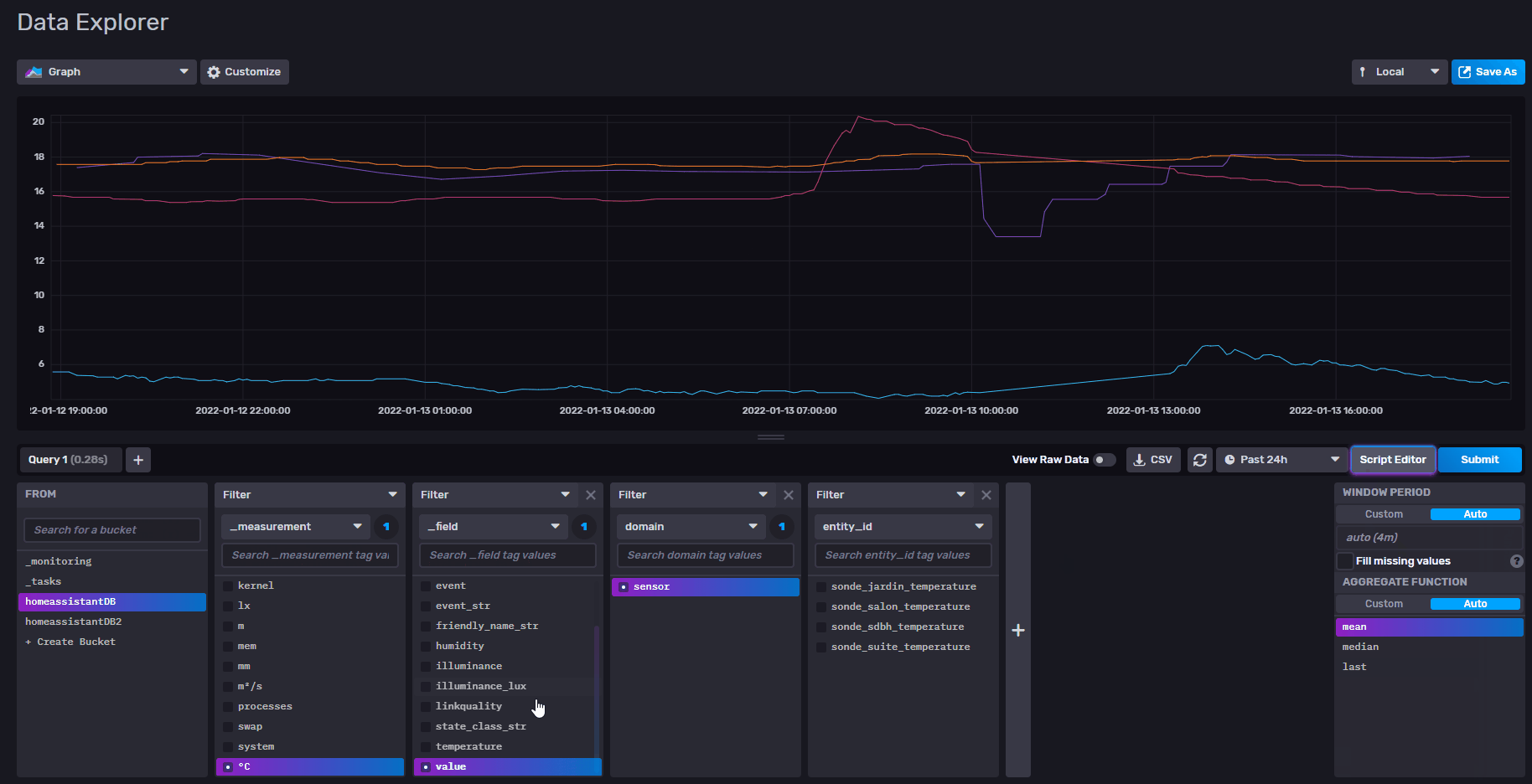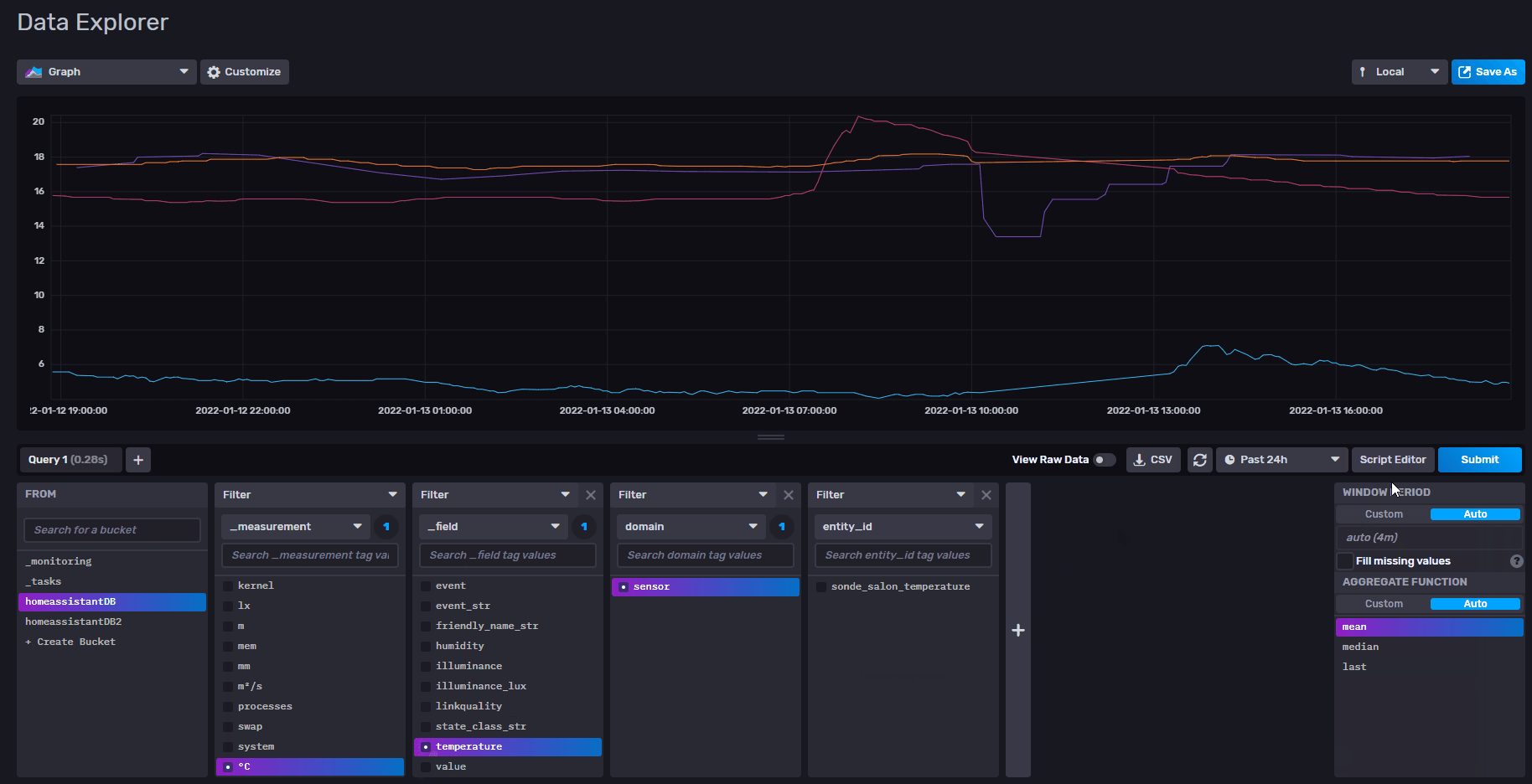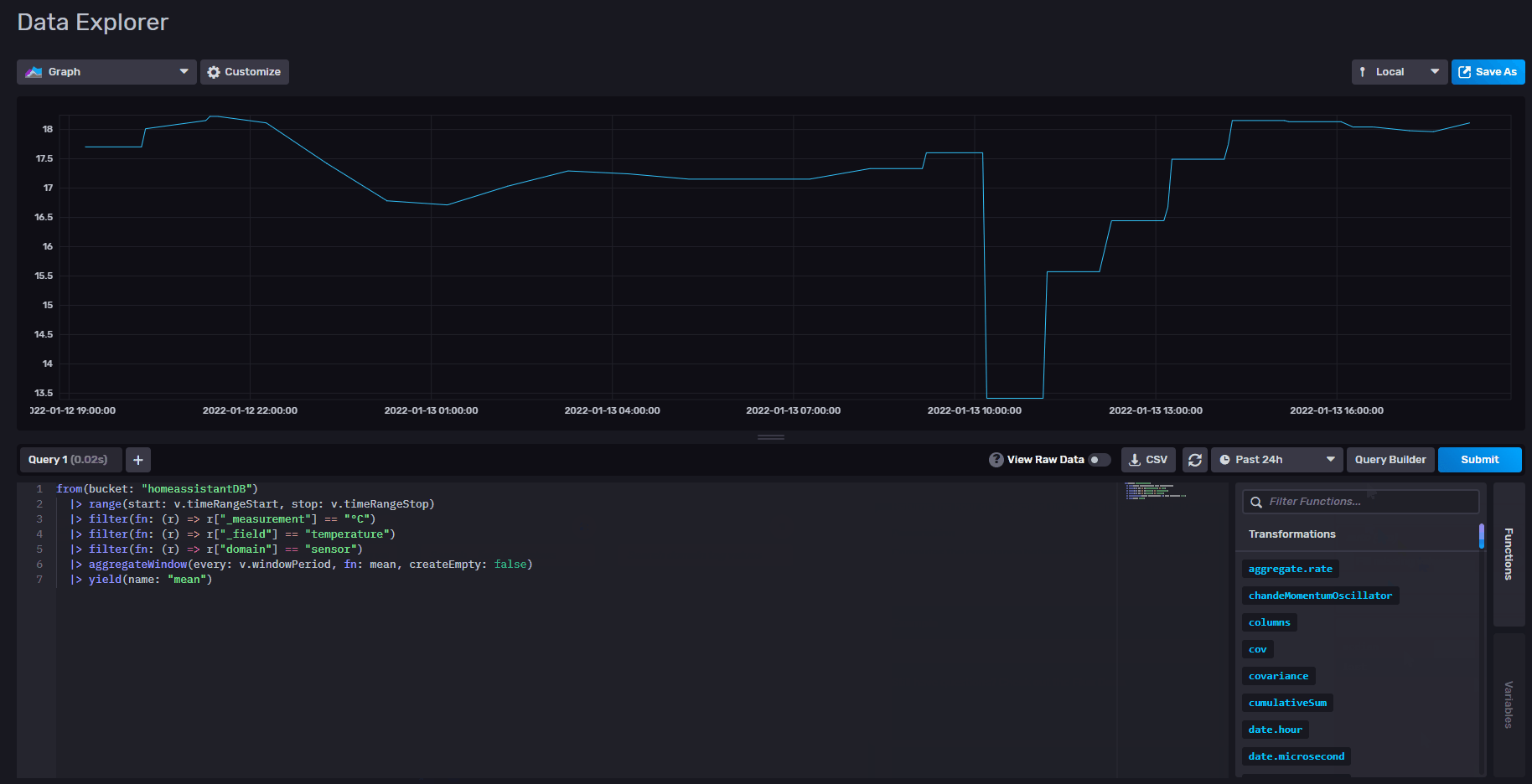
pour le reste effectivement c’est pas fluide
Salut @golfvert ,
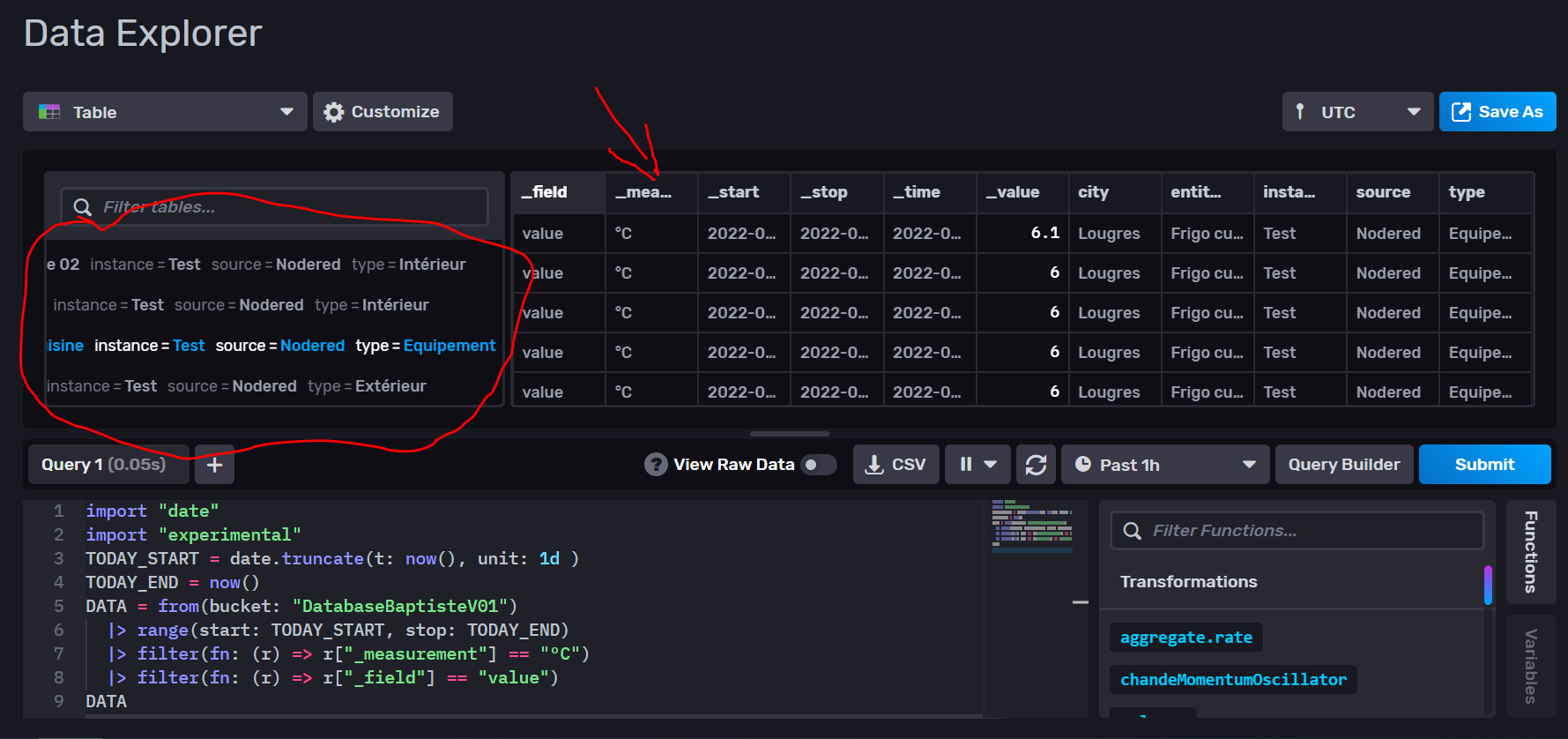
Bon visiblement c’est beaucoup plus simple que prévu, il suffit de réduire le filtre de sélection pour prendre toute les tables et cela fait le calcul table par table, exactement ce que je voulais.
-
Par exemple si je sélectionne toute mes données, cela me donne 5 tables (entourés en rouge) qui chacune contient une série de donnée (flèche rouge).
-
Si maintenant j’applique par exemple le calcul de la moyenne sur ce résultat, j’obtiens bien une valeur par table correspondant à la moyenne.

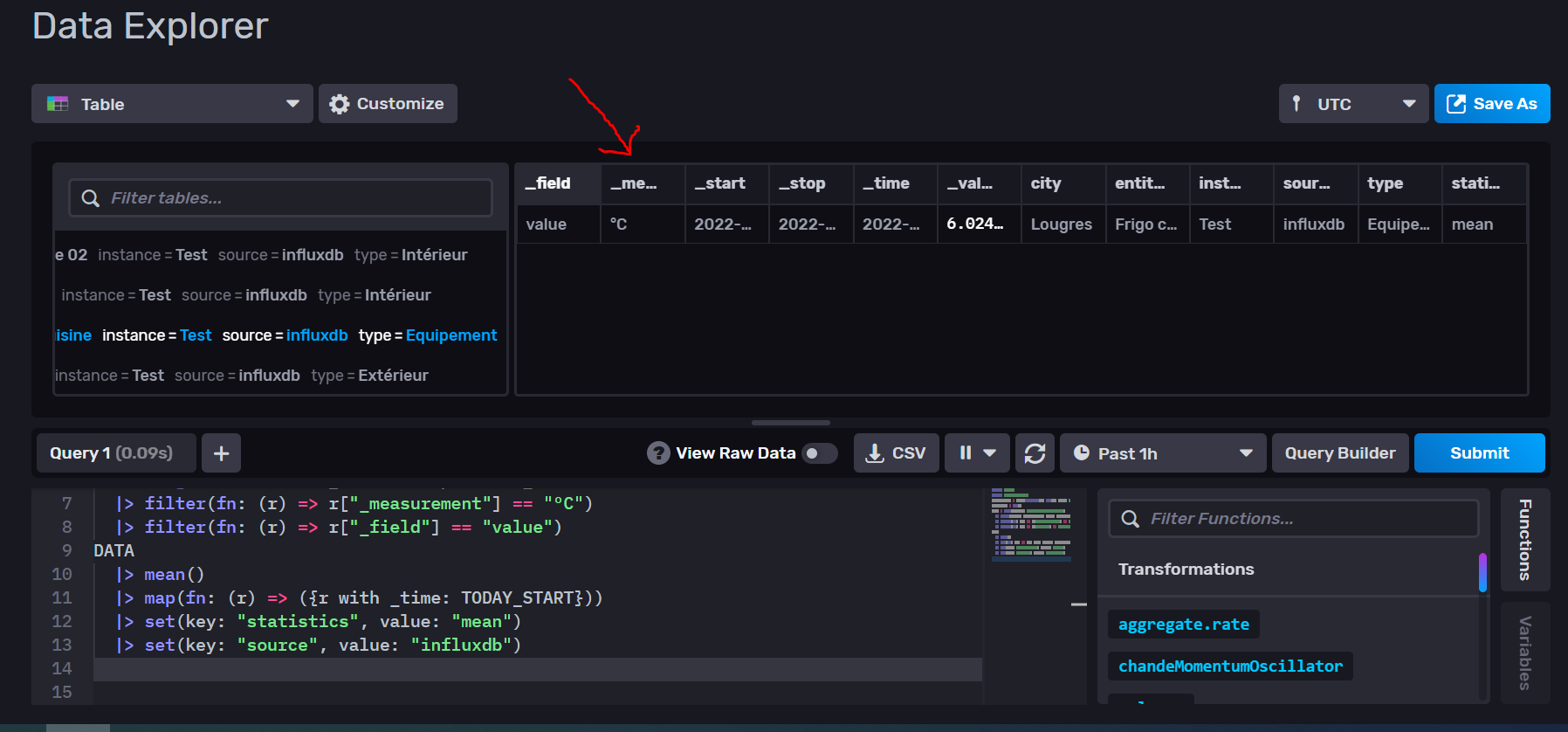
Du coup j’ai mis à jour ma « task » si cela intéresse quelqu’un :
- Correction du CRON
- Simplification des filtres pour prendre en compte l’ensemble des tables
- Arrondi des valeurs min/mean/max à 1 chiffre après la virgule via math.round
import "date"
import "experimental"
import "math"
option task = {name: "Daily_stat-v01", cron: "0 1 * * *"}
TODAY = date.truncate(t: now(), unit: 1d)
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
DATA = from(bucket: "DatabaseBaptisteV01")
|> range(start: YESTERDAY, stop: TODAY)
|> filter(fn: (r) =>
(r["_measurement"] == "°C"))
|> filter(fn: (r) =>
(r["_field"] == "value"))
DATA
|> mean()
|> map(fn: (r) =>
({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "mean")
|> set(key: "source", value: "influxdb")
|> map(fn: (r) =>
({r with _value: math.round(x: r._value * 10.0) / 10.0}))
|> to(bucket: "DatabaseBaptisteV02")
DATA
|> min()
|> map(fn: (r) =>
({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "min")
|> set(key: "source", value: "influxdb")
|> to(bucket: "DatabaseBaptisteV02")
DATA
|> max()
|> map(fn: (r) =>
({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "max")
|> set(key: "source", value: "influxdb")
|> to(bucket: "DatabaseBaptisteV02")
[EDIT] :
- Le calcul a bien eu lieu à 1h00 ce matin pour l’ensemble de mes capteurs !
- Plus qu’à exploiter le visuel sous grafana maintenant…
1 « J'aime »
Bien joué.
Du coup j’ai fait ça aussi à l’arrache et ça fonctionne.
Micro optimisation de mon côté, mettre les bd source et destination en variable.
Il doit y avoir moyen de faire une fonction pour faire les 3 opérations, je chercherai ce week-end
import "date"
import "experimental"
import "math"
option task = {
name: "Downsample Températures",
cron: "0 1 * * *",
}
TODAY = date.truncate(t: now(), unit: 1d)
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
FROM_DB = "homeassistantDB"
TO_DB = "homeassistantDB2"
DATA = from(bucket: FROM_DB)
|> range(start: YESTERDAY, stop: TODAY)
|> filter(
fn: (r) => r["_measurement"] == "°C",
)
|> filter(
fn: (r) => r["_field"] == "value",
)
DATA
|> mean()
|> map(
fn: (r) => ({r with _time: YESTERDAY}),
)
|> set(key: "statistics", value: "mean")
|> set(key: "source", value: "influxdb")
|> map(
fn: (r) => ({r with _value: math.round(x: r._value * 10.0) / 10.0}),
)
|> to(bucket: TO_DB)
DATA
|> min()
|> map(
fn: (r) => ({r with _time: YESTERDAY}),
)
|> set(key: "statistics", value: "min")
|> set(key: "source", value: "influxdb")
|> to(bucket: TO_DB)
DATA
|> max()
|> map(
fn: (r) => ({r with _time: YESTERDAY}),
)
|> set(key: "statistics", value: "max")
|> set(key: "source", value: "influxdb")
|> to(bucket: TO_DB)
1 « J'aime »
Hello !
Je partage ma tâche bricolé hier soir pour extraire ma consommation journalière d’électricité dans une seconde base :
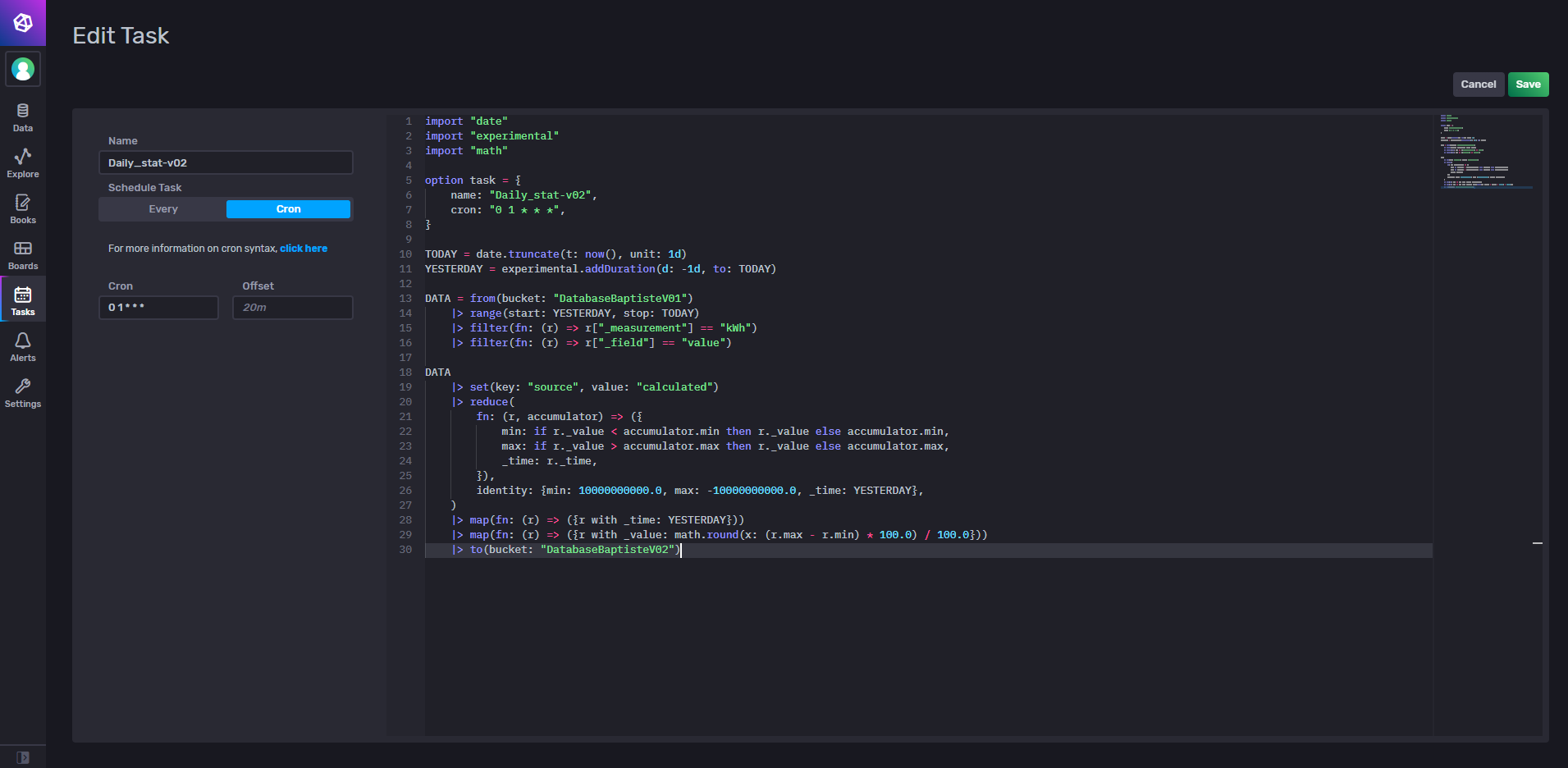
Le code :
import "date"
import "experimental"
import "math"
option task = {
name: "Daily_stat-v02",
cron: "0 1 * * *",
}
TODAY = date.truncate(t: now(), unit: 1d)
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
DATA = from(bucket: "DatabaseBaptisteV01")
|> range(start: YESTERDAY, stop: TODAY)
|> filter(fn: (r) => r["_measurement"] == "kWh")
|> filter(fn: (r) => r["_field"] == "value")
DATA
|> set(key: "source", value: "calculated")
|> reduce(
fn: (r, accumulator) => ({
min: if r._value < accumulator.min then r._value else accumulator.min,
max: if r._value > accumulator.max then r._value else accumulator.max,
_time: r._time,
}),
identity: {min: 10000000000.0, max: -10000000000.0, _time: YESTERDAY},
)
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> map(fn: (r) => ({r with _value: math.round(x: (r.max - r.min) * 100.0) / 100.0}))
|> to(bucket: "DatabaseBaptisteV02")
Ce qui donne :
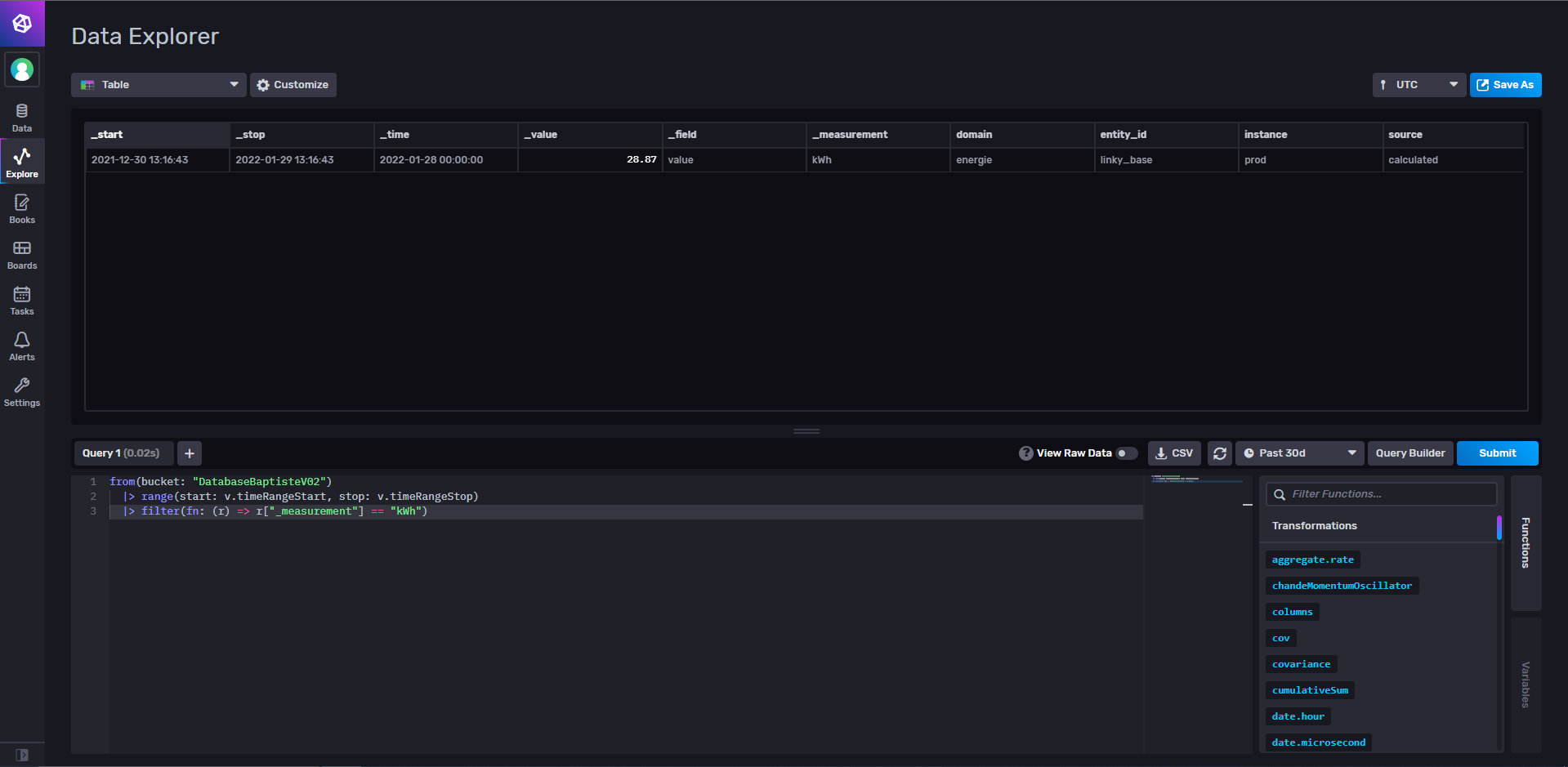
Hello,
@Pulpy-Luke , @Neuvidor , il y aurait moyen de nous faire un petit tuto de A à Z pour mettre cela en place SVP?
Je suis perdu du coup avec tous les échanges ^^
Merci d’avance!!
@Galadan
J’ai prévu de faire ça dans les mois à venir, je ne suis pas prêt pour le moment.
1 « J'aime »
Top !!
Merci beaucoup ![]()
Je pense que je vais devoir ouvrir un poste pour éviter de polluer celui-ci à l’avenir mais il faut me comprendre, j’aime partager mes avancées sur ce forum chaleureux ![]()
Coté InfluxDB :
- J’ai mis de l’ordre dans mes tasks :
- J’ai mis de l’ordre dans mes buckets :
Coté grafana :
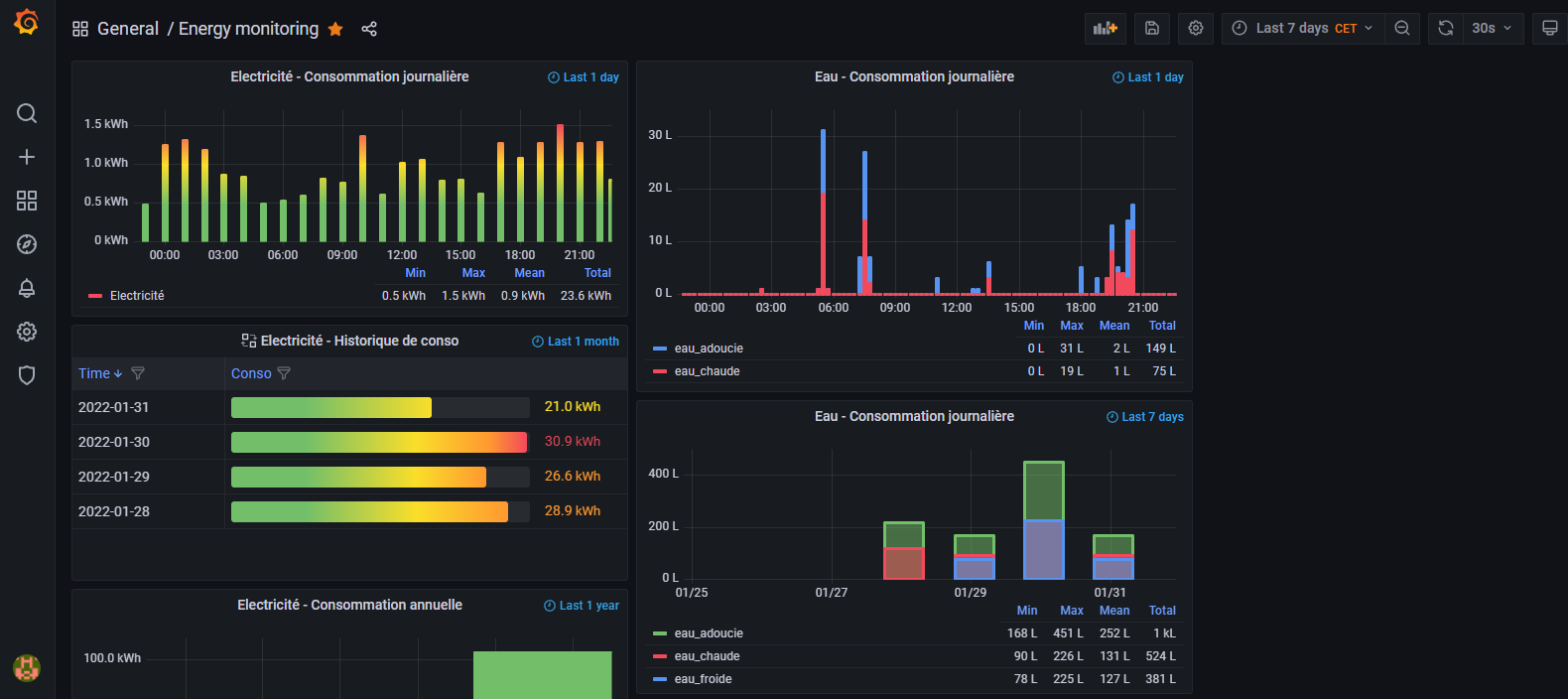
- Je commence à le prendre en main, voici mon premier dashboard :
Pour conclure :
J’ai organisé mes buckets en fonction de la tache que je leur associe :
- Bucket n°1 => Données brutes, un enregistrement par minute, les données sont effacées au bout de 30jours
- Bucket n°2 => Données traitées, un enregistrement par jour contenant les statistiques (min, max, moyenne, conso, …), stockage moyen terme
- Bucket n°3 => Données traitées, un enregistrement par mois contenant les statistiques (min, max, moyenne, conso, …), stockage très long terme
- Bucket n°4 => Données traitées, un enregistrement par année contenant les statistiques (min, max, moyenne, conso, …), stockage très long terme
5 « J'aime »
Hello,
J’ai ce message dans les log influxdb:
ts=2022-12-19T10:18:41.737885Z lvl=info msg=Unauthorized log_id=0erSOQIl000 error="authorization not found"
ts=2022-12-19T10:19:50.039843Z lvl=info msg=Unauthorized log_id=0erSOQIl000 error="authorization not found"
Peut-être que j’ai pas la partie cli d’installée mais, je ne sais pas comment faire…
Je suis en docker sur un Synology.
Merci pour votre aide.
P.S: trouvé, problème de token …
bonjour
avec votre aide j’ai réussi à me faire des task qui me permettent de générer histogrammes par heure, jour pour mes consommations. La logique est tjs la même, je récupère le min, le max et on fait la différence des 2.
mais j’ai un soucis, car je me base de l’index de mon ecodevice RT2, et parfois, il me renvoie des valeurs « fausse » (soit il les envoies, soit c’est HA qui les range mal car sous domoticz je n’avais pas ce souci) je me retrouve avec des consommations en MWh… Je n’arrive pas à savoir d’où ca vient (je vais ouvrir un topic à ce sujet) donc en palliatif au lieu de faire le min et max d’une période, je souhaite plutôt récupérer la valeur à une heure précises puis 1h plus tard et faire la différence des 2 : toutes les heures faire la différence entre la valeur de l’heure H et H-1. (et pour les conso journalière, récupérer la valeur à 00h00 et à 23h59 et faire la différence).
L’un de vous saurait comment faire un telle task sous Influxdb v2 ?
merci
Bonjour à tous
Juste une question je vois du chronograph, du télégraf mais est-ce nécessaire ?
Du moment que l’on a les données qui arrivent directement dans InfluxDB
J’ai mes proxmox qui arrivent directement sur influx dans 2 bucket différents, HA pareil et mon Jeedom (plus ancien) aussi
Est-ce que cela joue sur la durée de rétention des données peut être ? Ou autre que je ne vois pas pour le moment
Bonjour
D’accord avec ton point de vue sur le fait d’utiliser les bon outil pour les bon besoins … après avoir archi simple avec tout dans ha peut aussi se defendre
Concernant la remontée dans ha des données influxdb … tu as utilisé quel composant ha ?
Salut @larod241,
Sujet un peu ancien mais j’ai une question en lisant ton post: comment se réalise la liaison entre HA et influxdb dans un docker CT à part ? T’es-tu basé sur un tuto ?
Merci.