C’est ce que je viens de faire et c’est parfait. J’ai récupéré la matière via un une sauvegarde HA plutôt que via samba.
Tout semble parfait.
![]()
Merci encore
C’est ce que je viens de faire et c’est parfait. J’ai récupéré la matière via un une sauvegarde HA plutôt que via samba.
Tout semble parfait.
![]()
Merci encore
Salut @Wanfr , @SNoof
Petit partage rapide pour confirmer que Node-RED gère bien le timestamp.
Je précise que je test actuellement InfluxDB v2.0 avec Node-RED non pas dans l’add-on de HA mais dans des containers LXC sous Proxmox. Avec ceci j’arrive à injecter des données avec une date antérieur. Voir mon sujet dédié içi !
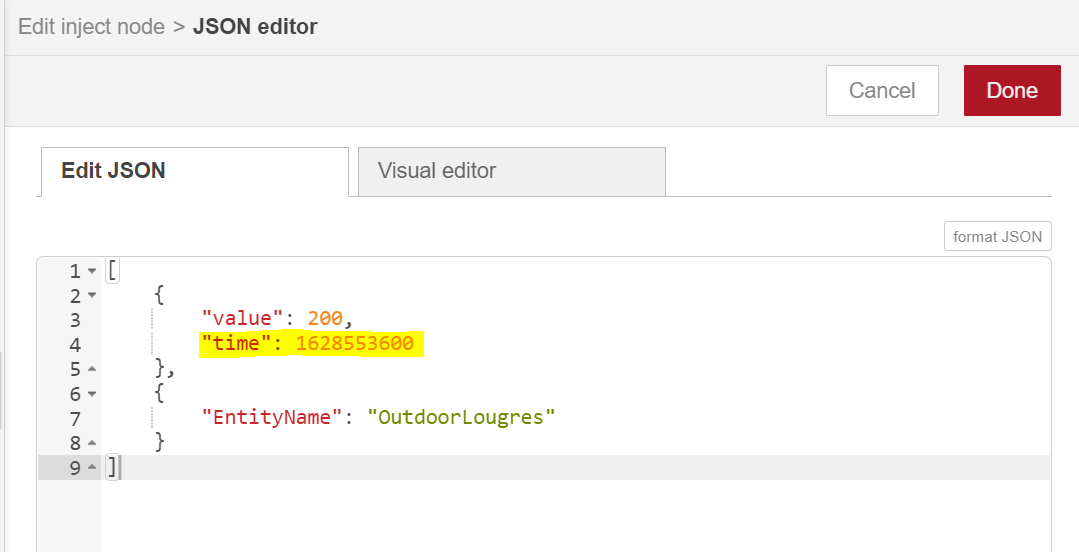
=> Mon node inject en JSON utilisé lors de mon test ce soir (ou matin je sais plus ![]() ) :
) :
=> Le timestamp correspond à la date suivante :
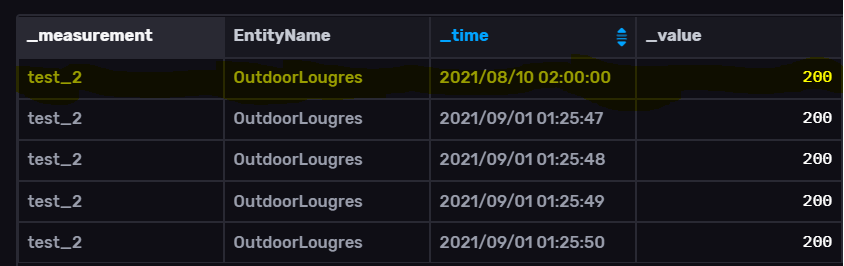
=> Ce qui donne dans influxDB (ligne en jaune) :
Hello
N’as-tu pas par hasard, un équivalent pour faire le downsample sur les données de la veille : le min, le max et la moyenne sur les 24H (donc 3 valeurs par jour)?
Je suis tombé sur ce truc qui permet à priori de faire les 3 calculs d’un coup, mais je bute sur le range et/ou le aggregateWindow
Pour ceux que ça interesse :
import "date"
TODAY = date.truncate(t: now(), unit: 1d)
DATA = from(bucket: "homeassistantDB/autogen")
|> range( start: -1d, stop: TODAY )
|> filter(fn: (r) => r._measurement == "°C")
|> filter(fn: (r) => r.entity_id == "sonde_jardin_temperature")
|> filter(fn: (r) => r["_field"] == "value")
time = now()
DATA
|> mean()
|> yield(name: "mean")
DATA
|> min()
|> yield(name:"min")
DATA
|> max()
|> yield(name:"max")
Ps. L’exemple de mon lien ci-dessus est correct. Il y a juste une coquille sur les doubles quotes qui n’en sont pas vraiment… Donc il faut les retransformer
C’est du flux là non ?
Donc influx 2 (ou 1.8 avec support flux actif…)
Perso j’ai toujours pas sauté le pas…
Exact influx2
Je pars de 0 donc plus simple.
Allez, une variante pour fixer la nouvelle date de valeur plus finement
import "date"
import "experimental"
TODAY = date.truncate(t: now(), unit: 1d)
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
DATA = from(bucket: "homeassistantDB/autogen")
|> range( start: YESTERDAY, stop: TODAY )
|> filter(fn: (r) => r._measurement == "°C")
|> filter(fn: (r) => r.entity_id == "sonde_jardin_temperature")
|> filter(fn: (r) => r["_field"] == "value")
time = now()
DATA
|> mean()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "_measurement", value: "°C")
|> set(key: "entity_id", value: "sonde_jardin_temperature_mean")
|> yield(name:"sonde_jardin_temperature_mean")
DATA
|> min()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "_measurement", value: "°C")
|> set(key: "entity_id", value: "sonde_jardin_temperature_min")
|> yield(name:"sonde_jardin_temperature_min")
DATA
|> max()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "_measurement", value: "°C")
|> set(key: "entity_id", value: "sonde_jardin_temperature_max")
|> yield(name:"sonde_jardin_temperature_max")
Le seul truc qui bloque encore c’est l’écriture dans le nouveau bucket (à la place du yeild)…
|> to(bucket: "homeassistantDB_downsampled/")
genere ça
Error: error calling function "to": function "to" is not implemented
![]()
EDIT:
C’est pas du 2.0 !!

Donc réécriture
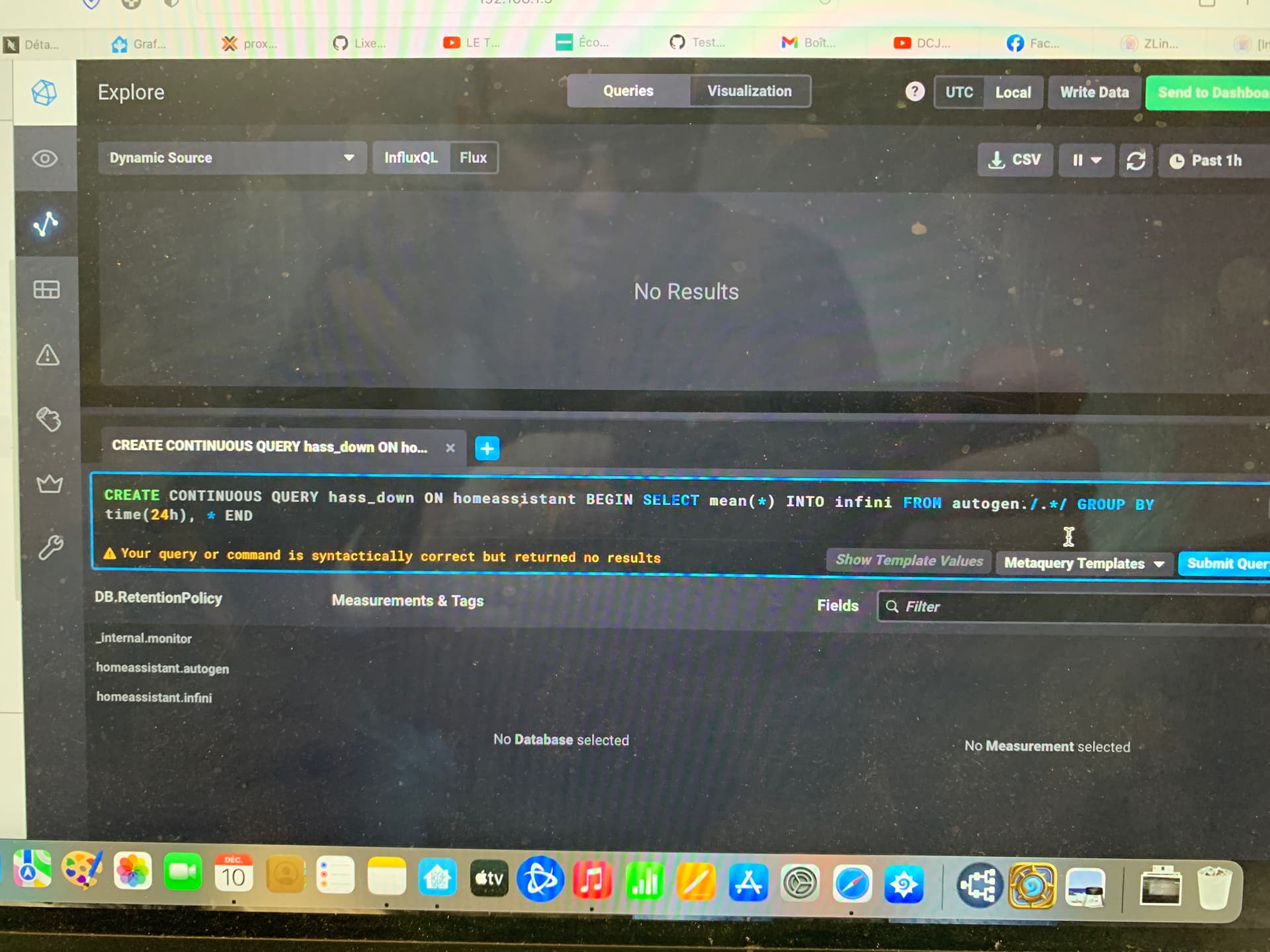
je viens de tomber sur ton post et je cherche a créer une DB longue durée. Mais je bute sur la continues queries!
ca me marque homeassistant.homeassistant not found. Je dois faire une erreur de syntaxe
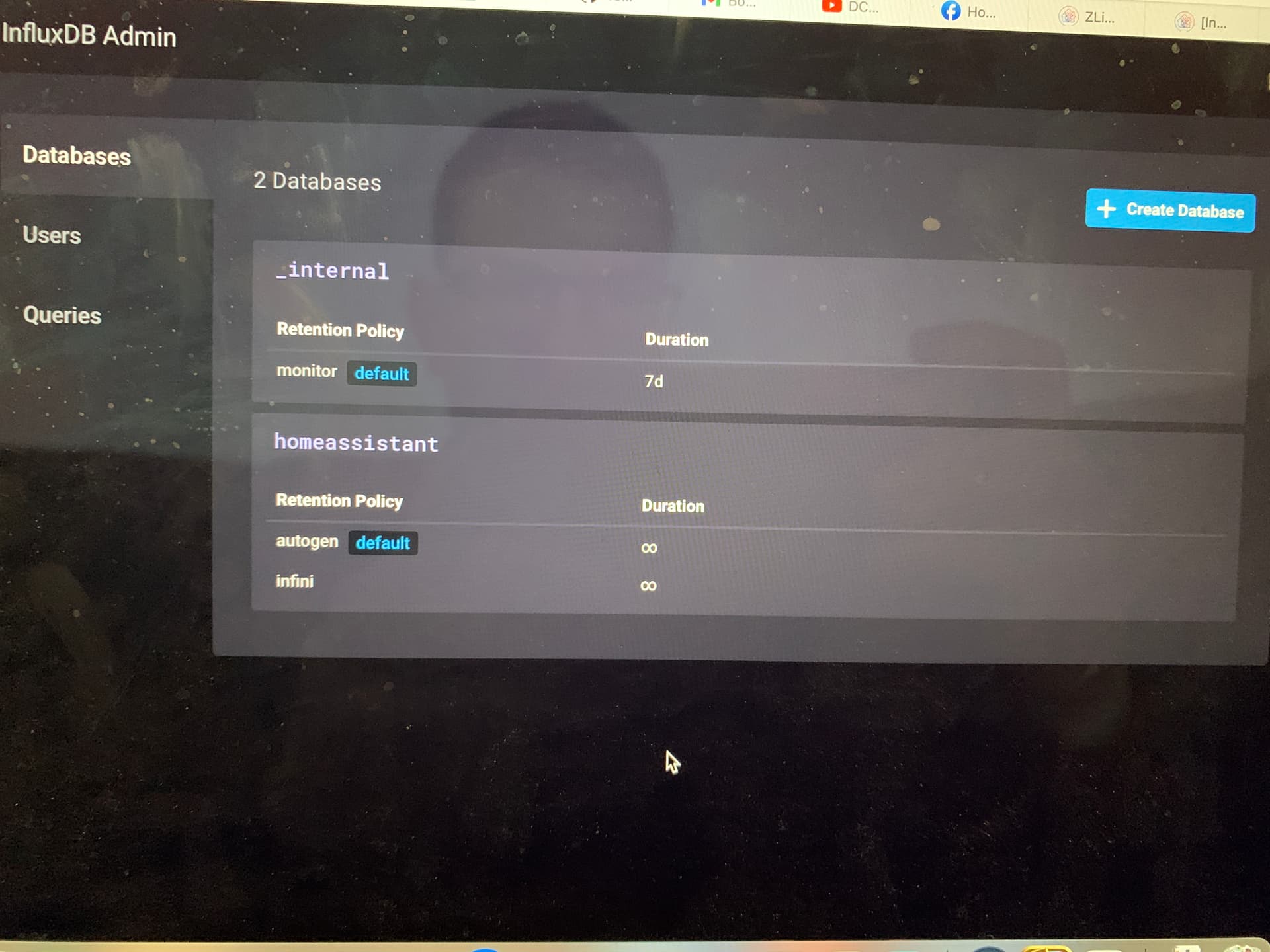
Voila une capture de l’écran
ma base automne est sur infini, je veux la réduire car ca commence a prendre pas mal de place ![]() mais je la réduirait une fois la continues queries mise en place et fonctionnelle
mais je la réduirait une fois la continues queries mise en place et fonctionnelle
et voila ce que j’ai dans le menu admin
EDIT: en virant les homeassistant de homeassistant.infini et de automne ca semble marcher.
Ca me met queries exist and syntax correct but return no result.
Dans Grafana si je regarde sur ma base infini je ne vois rien, par exemple avec des temperatures un graph qui marche sur ma base automne, je change de base il affiche aucune data, et meme en mettant mean_value comme tu recommande rien ne s’affiche.
InfluxDb et Grafana restent assez obscurs en fonctionnement pour moi. J’arrive juste a afficher des graphs de ce que je cherche
ou peut on voir les continuesqueries ? pour éventuellement les modifier
j’ai réussi avec ca en requête. Si ca peut aider
CREATE CONTINUOUS QUERY hass_down ON homeassistant BEGIN SELECT mean() INTO homeassistant.infini.:MEASUREMENT FROM homeassistant.autogen././ GROUP BY time(1d), * END
Ca me groupe dans une autre db par 24h mes mesures. Suffisante pour garder une trace des temperatures ou de ma Conso électrique …
maintenant je cherche a copier les data actuelles de ma BD vers la nouvelle (infini) en faisant la meme moyenne. mais je suis toujours a taton sur la syntaxe…
Bonjour,
J’aurais besoin de l’aide d’un spécialiste pour des requêtes flux sur ma DB.
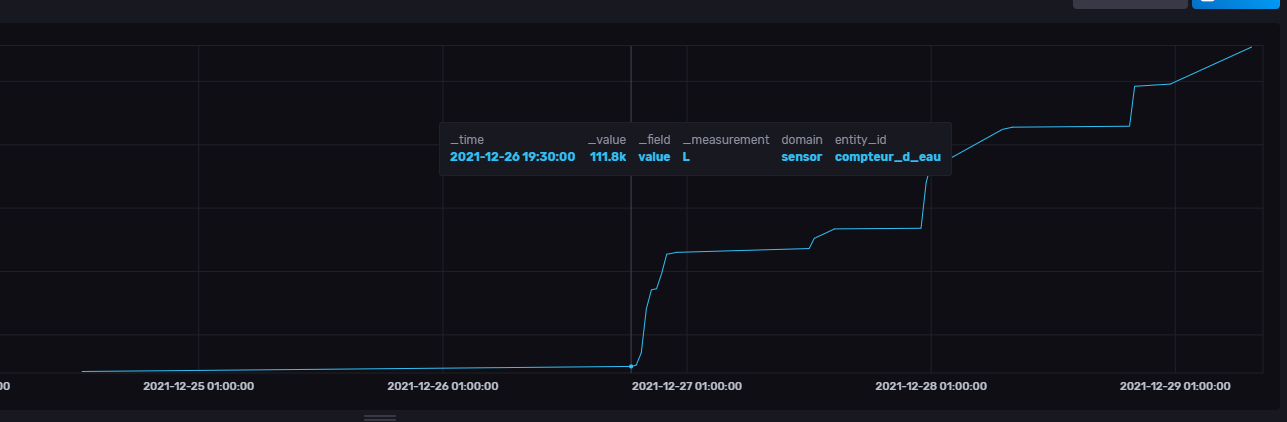
J’ai un compteur d’eau impulsionnel 1l/imp, je récupère bien les données dans mon InfluxDB:
from(bucket: "GalaHome")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "L")
|> filter(fn: (r) => r["_field"] == "value")
|> filter(fn: (r) => r["domain"] == "sensor")
|> filter(fn: (r) => r["entity_id"] == "compteur_d_eau")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")
J’aimerais faire un histogramme journalier de mon consommation d’eau.
Je ne sais pas comment mettre cela en place…
Merci de votre aide! ![]()
Bonjour,
En ce qui me concerne, j’ai une question par rapport à ceci :
Je cite SNoof :
Du coup, j’ai tout changé, mes datas de télérelève sont extraites par nodered, puis envoyées direct dans influxdb. Et HA, récupère quelques unes de ces valeurs pour les afficher sur lovelace. Mais il n’est pas en charge de transmettre quoi que ce soit.
Si j’ai bien compris, dans ce cas, il ne faut pas inclure influxdb dans le fichier configuration.yaml mais uniquement envoyer les données que l’on souhaite stocker à partir de nodered. On utilise le fichier configuration.yaml uniquement pour définir les sensors contenant les données qu’on veut récupérer dans lovelace. C’est bien correct ?
Je vous remercie.
Pascal
Super cool ton premier jet @Pulpy-Luke,
Pour ma part j’ai du mettre en pause mon travail, je recommence seulement donc il faut déjà que je raccroche les wagons de mon propre travail…
Du coup tu as réussi à extraire les min, max, average des données sur la v2.0 ? J’ai pas compris ton « Édit » indiquant la v1. 8
J’ai mis le sujet de coté aussi… j’aime pas les bases de données à la base ![]()
En fait, en passant par chronograph, on peut faire de la syntaxe v1 ou v2… J’ai pondu le truc en v2 mais la base influxbd (l’addon HA est en v1)… et donc forcement l’écriture en base plante. Refaire ça en V1… ![]() .
.
Techniquement le meilleur choix technique serait de supprimer la dépendance HA (v1) et faire mon propre container influxdb (v2)… et reintégrer les dashboards grafana (container maison aussi) par la suite … Pas motivé pour le coup
OK merci.
Pour ma part je vais persister en InfluxDB v2 hors de HA pour justement ne pas avoir de dépendance avec celui-ci. J’ai la tête dure… ![]()
Même si je crois en HA, j’ai envie d’avoir une solution robuste et généraliste concernant l’archivage des données au cas où. (compatible tout système domotique).
Pour le moment je relis mes précédents échanges alors tu vois… Je n’ai malheureusement pas encore le temps de véritablement continuer alors j’en profite pour faire un coucou à la communauté.
Je ne désespère pas d’avoir un jour le temps de finir mais comme je n’ai jamais fais de base de données jusque là, je pars de zéro… ![]() Enfin comme on dit, avec le temps, tous s’apprend !
Enfin comme on dit, avec le temps, tous s’apprend !
Super tuto merci a toi.
Bon, j’ai joué aujourd’hui :
Bilan :
Bref… c’est pour l’instant pas beaucoup plus exploitable
Docker-compose.yaml
version: '3'
########################################################
networks:
influxdb:
name: ${COMPOSE_PROJECT_NAME}
########################################################
services:
influxdb:
image: influxdb:latest
hostname: influxdb
restart: unless-stopped
# expose:
# - "8083"
# - "8086"
# - "8090"
# - "2003"
ports:
- 8086:8086
volumes:
- ./data/influxdb:/var/lib/influxdb2
- ./config/influxdb/:/etc/influxdb2
environment:
- TIMEZONE=Europe/Paris
- INFLUXD_REPORTING_DISABLED=true
- DOCKER_INFLUXDB_INIT_MODE=setup
# - DOCKER_INFLUXDB_INIT_MODE=upgrade
- DOCKER_INFLUXDB_INIT_USERNAME=${INFLUXDB_ADMIN_USERNAME}
- DOCKER_INFLUXDB_INIT_PASSWORD=${INFLUXDB_ADMIN_PASSWORD}
- INFLUXDB_ADMIN_ENABLED=true
- DOCKER_INFLUXDB_INIT_ORG=${INFLUXDB_ORG}
- DOCKER_INFLUXDB_INIT_BUCKET=${INFLUXDB_BUCKET}
- DOCKER_INFLUXDB_INIT_ADMIN_TOKEN=${INFLUXDB_ADMIN_TOKEN}
- DOCKER_INFLUXDB_INIT_RETENTION=1w
- INFLUXDB_HTTP_AUTH_ENABLED=true
networks:
- influxdb
chronograf:
image: chronograf:latest
hostname: chronograf
restart: unless-stopped
ports:
- 8888:8888
volumes:
- ./data/chronograf:/var/lib/chronograf
command: ["chronograf", "--influxdb-url=http://influxdb:8086"]
depends_on:
- influxdb
environment:
- TIMEZONE=Europe/Paris
- INFLUXDB_URL=http://influxdb:8086
- INFLUXDB_USERNAME=${INFLUXDB_ADMIN_USERNAME}
- INFLUXDB_PASSWORD=${INFLUXDB_ADMIN_PASSWORD}
networks:
- influxdb
le .env
COMPOSE_PROJECT_NAME=tick
INFLUXDB_ADMIN_USERNAME=admin
INFLUXDB_ADMIN_PASSWORD=MUJsa4bYAVMheXRw
INFLUXDB_ORG=myorg
INFLUXDB_BUCKET=homeassistantDB
INFLUXDB_ADMIN_TOKEN=0_405Sz4xqcwOylqAG1tZfNzfL4yidgw-1SNvydiH3gT8QVqcewccoabAIoNgBrvY9HhmoOjHkWrwq8UUhdc3w==
C’est pas propre propre mais bon
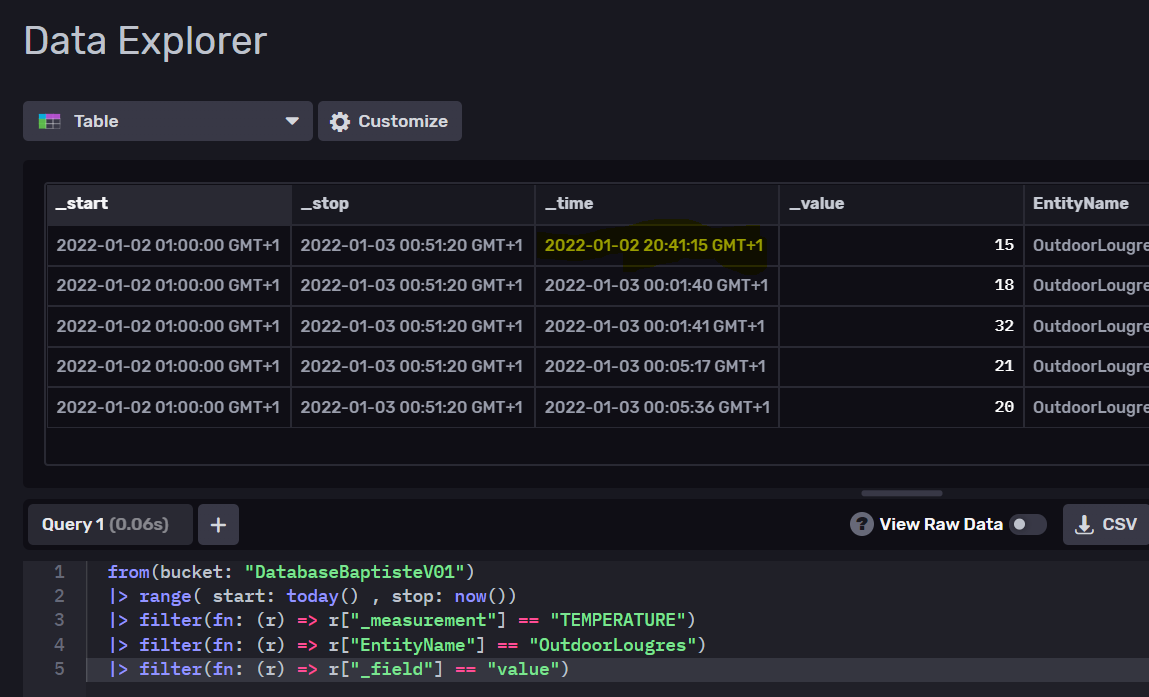
Salut @Pulpy-Luke ,
As-tu vérifié concernant ton code si le range des données était bien respecté ?
Pour ma part je viens de m’apercevoir que le range ne s’applique pas à la colonne « _time », il faut apparemment utiliser un filtre sur cette dernière pour que cela fonctionne. La colonne « _time » correspond au timestamp que je précise lors de l’écriture via nodered.
Par exemple ci-dessous j’ai sélectionné les données d’aujourd’hui et pourtant cela me retourne une valeur du jour précédent (en jaune).
A creuser donc…
Les min max moy que j’avais était cohérents sur la journée en cours, mais c’est tout à fait possible que ça ne soit pas bon partout. Je ne suis focalisé dans un premier temps sur l’insertion dans la table downsampled… Donc j’ai pas vérifié si les données de départ étaient parfaitement alignées
J’ai trouvé un exemple dans la doc influxDB v2.1 qui est proche de mon besoin, j’espère pouvoir essayer ça ce soir. ![]()
=> https://docs.influxdata.com/influxdb/v2.1/process-data/common-tasks/calculate_weekly_mean/
Je te laisse tester… Le to(bucket) c’est à mon avis le même point bloquant si la base n’est pas en v2