Donc les imports, c’est simplement pour pouvoir utiliser les fonctions date.truncate() et experimental.addDuration()
Si on rapproche ça de NR, ça pourrait correspondre à 2 palettes date et experimental avec chacun un node , respectivement truncate et addDuration
Quant au bug
OK, j’avais un doute à cause du bug… (Que j’ai pas chez moi c’est le resultat normal ![]() ) avec juste l’image, c’est pas possible de dire quoique ce soit, on ne voit pas la requête faite … mais sur le principe, oui il faut calculer la date de la veille ou lancer l’action à 23H59
) avec juste l’image, c’est pas possible de dire quoique ce soit, on ne voit pas la requête faite … mais sur le principe, oui il faut calculer la date de la veille ou lancer l’action à 23H59
Pour le « souci » de date, tout est stocké en UTC et nous sommes en UTC+1 d’ou le décalage…
1 « J'aime »
J’ai suivi ce que tu as fait @Pulpy-Luke :
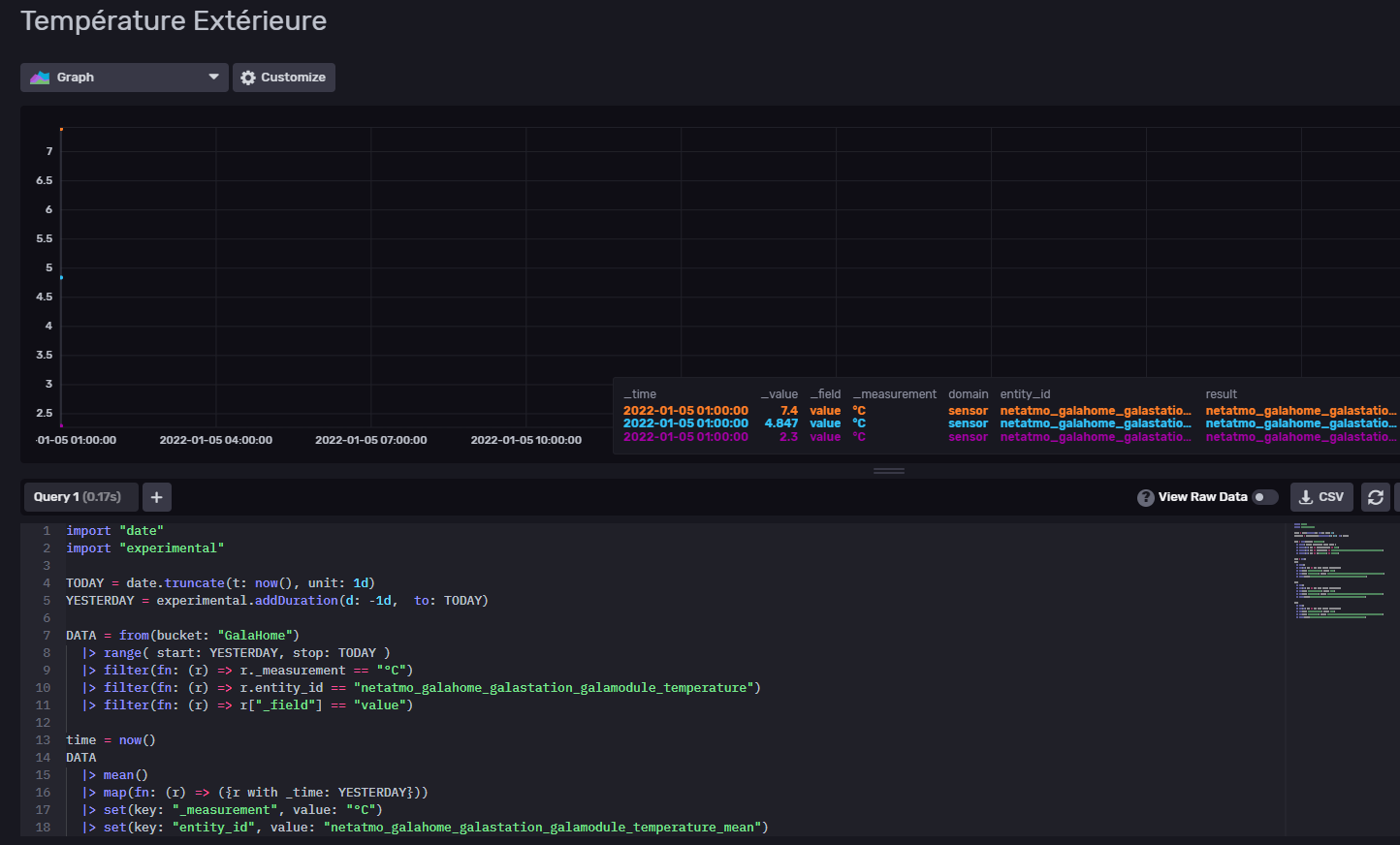
J’ai pas de courbe mais je suppose qu’il faut que j’ai deux jours de relevé?
Et comment peut-on faire ce relevé a une heure précise (23h59/jours)?
J’ai réussi a bricoler cela @SNoof :

Mais les données ne sont pas tout a fait juste car le relevé est à 1h du mat du coup, je trouve pas comment contourner le problème.
Surement que les deux choses sont liées ^^
Salut @Pulpy-Luke ,
J’ai à nouveau essayé et j’avoue ne pas reproduire le problème, étrange car je n’ai pas
J’ai aussi créé un second « Bucket » afin d’exporter le résultat et cela fonctionne bien, la valeur est bien exportée.
Voici mon code (sur la base du tien) :
import "date"
import "experimental"
TODAY = date.truncate(t: now(), unit: 1d )
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
DATA = from(bucket: "DatabaseBaptisteV01")
|> range(start: YESTERDAY, stop: TODAY)
|> filter(fn: (r) => r["_measurement"] == "°C")
|> filter(fn: (r) => r["_field"] == "value")
|> filter(fn: (r) => r["instance"] == "Test")
|> filter(fn: (r) => r["entity_id"] == "Jardin")
|> filter(fn: (r) => r["city"] == "Lougres")
DATA
|> mean()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "_measurement", value: "°C")
|> set(key: "entity_id", value: "Jardin")
|> set(key: "statistics", value: "mean")
|> set(key: "source", value: "influxdb")
|> set(key: "city", value: "Lougres")
|> to(bucket: "DatabaseBaptisteV02")
DATA
|> max()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "_measurement", value: "°C")
|> set(key: "entity_id", value: "Jardin")
|> set(key: "statistics", value: "max")
|> set(key: "source", value: "influxdb")
|> set(key: "city", value: "Lougres")
|> to(bucket: "DatabaseBaptisteV02")
DATA
|> min()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "_measurement", value: "°C")
|> set(key: "entity_id", value: "Jardin")
|> set(key: "statistics", value: "min")
|> set(key: "source", value: "influxdb")
|> set(key: "city", value: "Lougres")
|> to(bucket: "DatabaseBaptisteV02")
Mes données dans le second bucket :
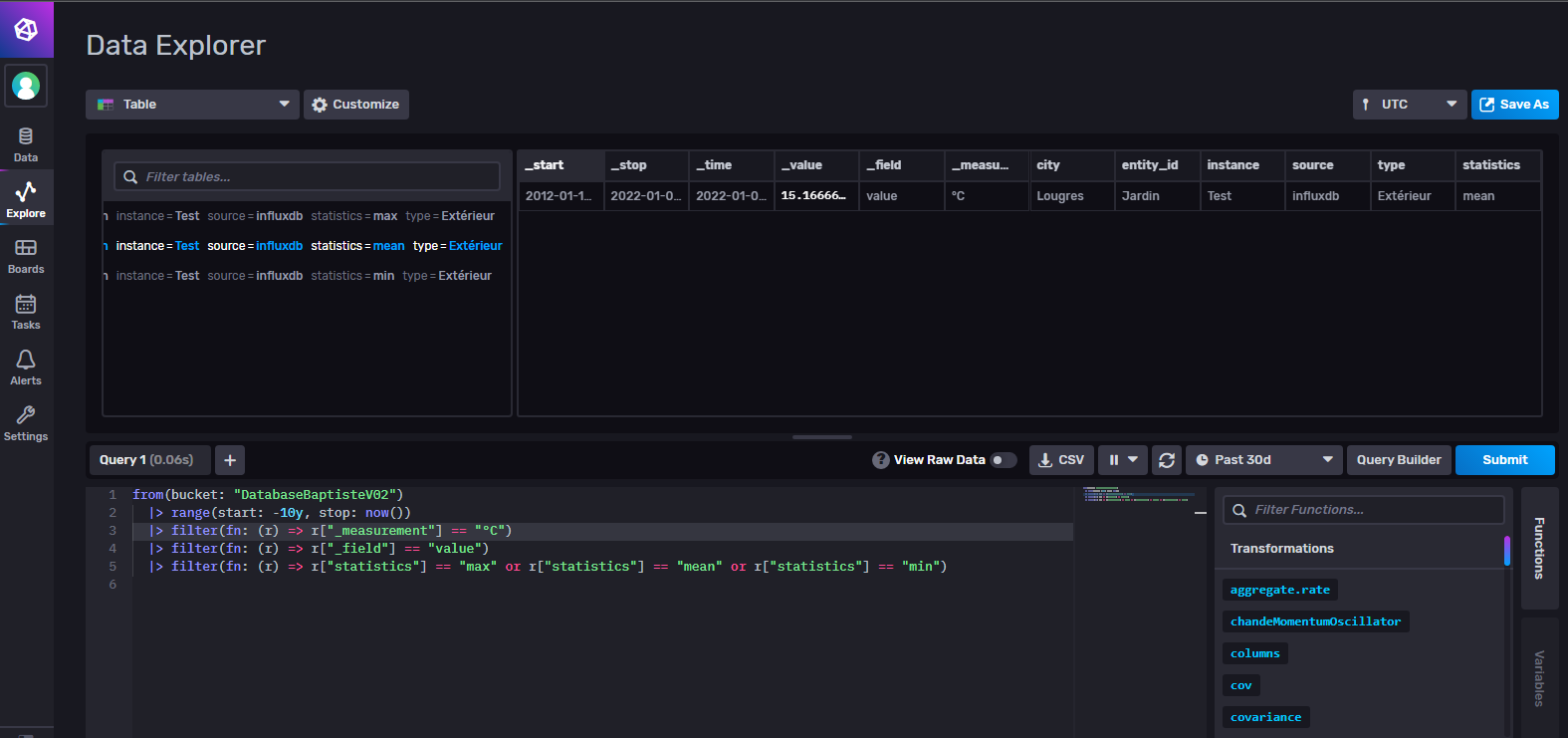
Le seul truc étrange est qu’il y a 1h de décalage entre le « _time » issue du script et celui réellement stocké dans le nouveau bucket alors que les 2 sont en UTC :
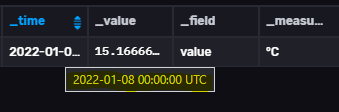
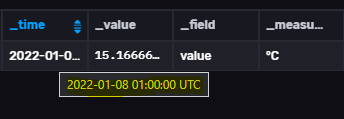
1 « J'aime »
Bizarre en effet… Bon après il faut voir l’impact 0H00 ou 1h00 c’est la même journée…
Je n’aime pas ne pas maîtriser mes requêtes, C’est surtout ça. Pourquoi le « to bucket » engendrerai un changement d’heure ?
Je suis pas sur que la cause ce soit le bucket…
En prenant les valeurs d’un bucket et en les écrivant direct dans l’autre, ça confirmera la piste
A mon avis il y a un UTC par défaut qui traine dans la manipulation des dates :
+1 à la lecture, mais le calcul de today/yesterday utilise du +0…
En exécutant le code suivant la date change très légèrement (insignifiant mais elle change) :

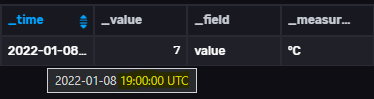
Le code :
from(bucket: "DatabaseBaptisteV01")
|> range(start: -1d, stop: -20h)
|> filter(fn: (r) => r["_measurement"] == "°C")
|> filter(fn: (r) => r["_field"] == "value")
|> filter(fn: (r) => r["instance"] == "Test")
|> filter(fn: (r) => r["entity_id"] == "Jardin")
|> to(bucket: "DatabaseBaptisteV02")
Calcul d’arrondi car pas un timestamp ?
En tout cas, ça semble confirmer la piste que le fuseau est inclus qq part dans les calculs de yesterday/today
Pas simple ce truc quand même
Pour le coup il y a bien un timestamp car j’ai importé la donnée via nodered justement en forçant le timestamp.
Un timestamp qui change d’un bucket à l’autre, c’est pas génial
Il y a forcément un truc que je loupe car ce serait surprenant quand même, surtout pour une base de données orientée séries temporelles
Bon tu me croiras ou pas mais en voulant créer un topic sur le forum influxdb dédié à ce bug, je n’ai pas réussi à le reproduire…
C’est mieux comme ça ![]()
Je vais finir par croire que je deviens fou, heureusement que les impressions d’écrans sont là pour me prouver à moi même que j’ai vu ces comportements ![]()
Quelles captures ? ![]()
![]()
Donc du coup, c’est un truc du package experimental qui manipule mal les TZ
1 « J'aime »
Je vais essayer de creuser en torturant un peu les manips et voir ce que « date.truncate » et « experimental.addDuration » donne. En tous cas d’après ce que j’ai lu dans la doc, cela est sensé bien fonctionner.
J’aime avancer petit à petit, doucement mais surement comme on dit. C’est une manière d’apprendre et un loisir pour moi ![]()
Du coup je viens de faire un test réel :
- Ecriture chaque minute de la température de mon jardin dans influxDB via nodered
- Attente pendant 2 jours
- Test du script ci-dessous qui fonctionne nikel !
import "date"
import "experimental"
TODAY = date.truncate(t: now(), unit: 1d )
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
DATA = from(bucket: "DatabaseBaptisteV01")
|> range(start: YESTERDAY, stop: TODAY)
|> filter(fn: (r) => r["_measurement"] == "°C")
|> filter(fn: (r) => r["_field"] == "value")
|> filter(fn: (r) => r["instance"] == "Test")
|> filter(fn: (r) => r["entity_id"] == "Jardin")
|> filter(fn: (r) => r["city"] == "Lougres")
DATA
|> mean()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "mean")
|> set(key: "source", value: "influxdb")
|> to(bucket: "DatabaseBaptisteV02")
DATA
|> min()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "min")
|> set(key: "source", value: "influxdb")
|> to(bucket: "DatabaseBaptisteV02")
DATA
|> max()
|> map(fn: (r) => ({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "max")
|> set(key: "source", value: "influxdb")
|> to(bucket: "DatabaseBaptisteV02")
Le résultat :
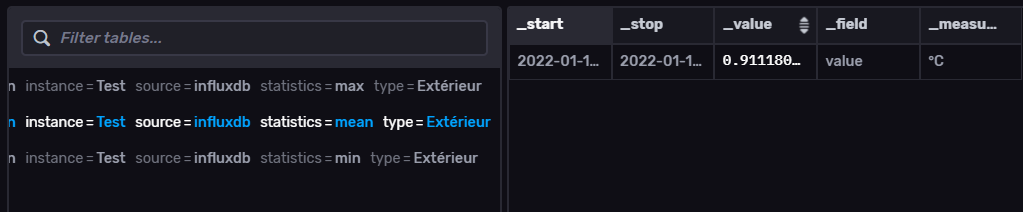
CONCLUSION
Reste plus qu’à trouver une manière d’exécuter le script en automatique et surtout trouver un moyen pour que le script effectue ceci pour chaque variable sans devoir répliquer le code…
2 « J'aime »
Bien joué…
Pour l’équivalent du cron c’est facile
Donc 1 ligne de plus
Du coup je viens de créer une tache qui tournera tous les jours à 1h du matin (UTC je pense).
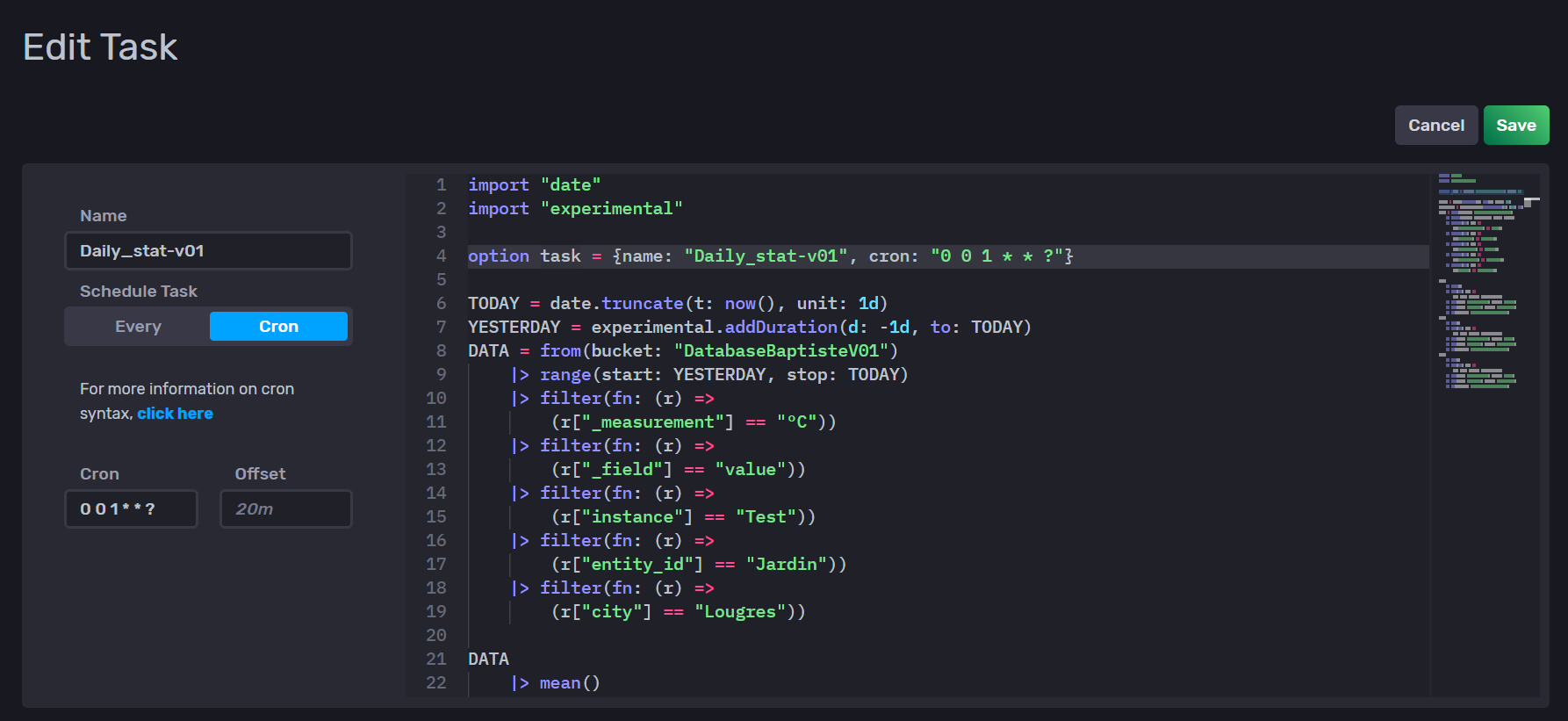
Le code :
import "date"
import "experimental"
option task = {name: "Daily_stat-v01", cron: "0 0 1 * * ?"}
TODAY = date.truncate(t: now(), unit: 1d)
YESTERDAY = experimental.addDuration(d: -1d, to: TODAY)
DATA = from(bucket: "DatabaseBaptisteV01")
|> range(start: YESTERDAY, stop: TODAY)
|> filter(fn: (r) =>
(r["_measurement"] == "°C"))
|> filter(fn: (r) =>
(r["_field"] == "value"))
|> filter(fn: (r) =>
(r["instance"] == "Test"))
|> filter(fn: (r) =>
(r["entity_id"] == "Jardin"))
|> filter(fn: (r) =>
(r["city"] == "Lougres"))
DATA
|> mean()
|> map(fn: (r) =>
({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "mean")
|> set(key: "source", value: "influxdb")
|> to(bucket: "DatabaseBaptisteV02")
DATA
|> min()
|> map(fn: (r) =>
({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "min")
|> set(key: "source", value: "influxdb")
|> to(bucket: "DatabaseBaptisteV02")
DATA
|> max()
|> map(fn: (r) =>
({r with _time: YESTERDAY}))
|> set(key: "statistics", value: "max")
|> set(key: "source", value: "influxdb")
|> to(bucket: "DatabaseBaptisteV02")