Je rencontre un problème depuis quelques jours : le disque se remplit à vue d’oeil (10 Go tous les 8h, ça peut être plus rapide). Je dois redémarrer HA pour retrouver un peu de souffle (environ 10 Go retrouvés après reboot).
Je n’arrive pas à comprendre d’où ça vient. Je suis à jour de la dernière version.
Côté logs, je ne prends que les notifications critical.
Les datas (qui sont certes volumineuses puisque je garde 1 an d’historique) représentent 45 Go, sont stockées sur MariaDB (dans un contenaire Docker sur HA).
Je suis donc preneur si vous avez des idées parce que je sèche !
Merci
Ta base de donnés doit tout enregistré , si tu as des sondes de température il se peux que celle-ci envoi des infos toutes les 1 minutes par exemples, et donc sa gonfle ta base …
donc un script qui purge ta BD, et affine tes reglages avec recorder.
Je comprends ton point de vue mais qu’est ce qui explique qu’après un reboot je retrouve 10 Go ?
Si tenté que ça soit une sonde un peu bavarde qui me cause ces pb, les enregistrements ne seraient pas supprimées au reboot.
Et puis surtout, mon install tourne depuis des mois sans que cela ne se soit rempli à cette vitesse…
Bjr
Ressemble plus à un pb de log qui grossit ( j’ai eu ce pb le pb le mois dernier a cause d’une clé USB mal installer sous proxmox. T’as rien installé ces derniets jours ?
Regarde la taille de tes logs " system"
je viens de redémarrer le serveur, j’ai regagné les 10 Go. Je viens de reperdre 100 Mo et le fichier home-assistant.log fait 3 Ko (puisque je n’ai demandé que les notif CRITICAL).
Donc a priori, c’est pas ça…
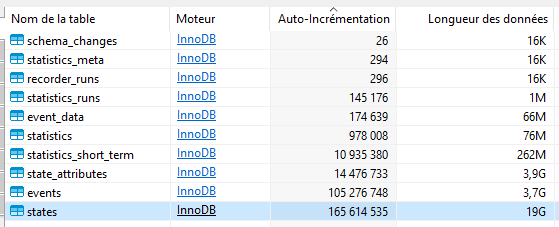
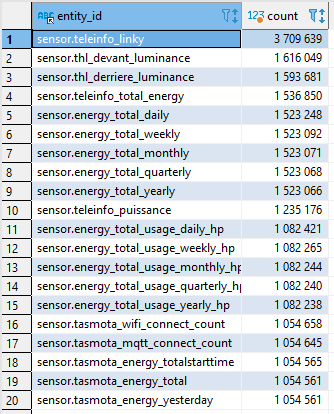
Je suis sur un base MariaDB donc c’est un peu différent mais sur le principe, avec d’autres outils, voici les résultats :
Etat de la BDD
Et le top 20 records :
Je pense que je vais lancer un grand nettoyage dans un premier temps même si je doute que ça soit ça le problème, sauf si au delà d’une certaine taille, HA le gère mal ?
Pour info, depuis le début de ce fil de discussion, j’ai pris 2 Go dans la vue !
Les fichiers home-assistant.log et les fichiers de journaux n’ont pas bougé…
Quelque chose déconne… c’est peut-être un des add-ons…
HA de base ne génère pas autant de choses sur le disque…
Just au hasard, c’est surement pas ça mais: Tu te ferais pas attaquer par un DDOS sur ton NGINX?
Essayes de stopper chacun de tes add-ons, à commencer par les non essentiels et après chaque arrêt, regardes si ton disque grossit encore aussi vite… puis passes au suivant…
Je commencerais pas InfluxDB, Grafana, Nginx, AdGuard, Glances…
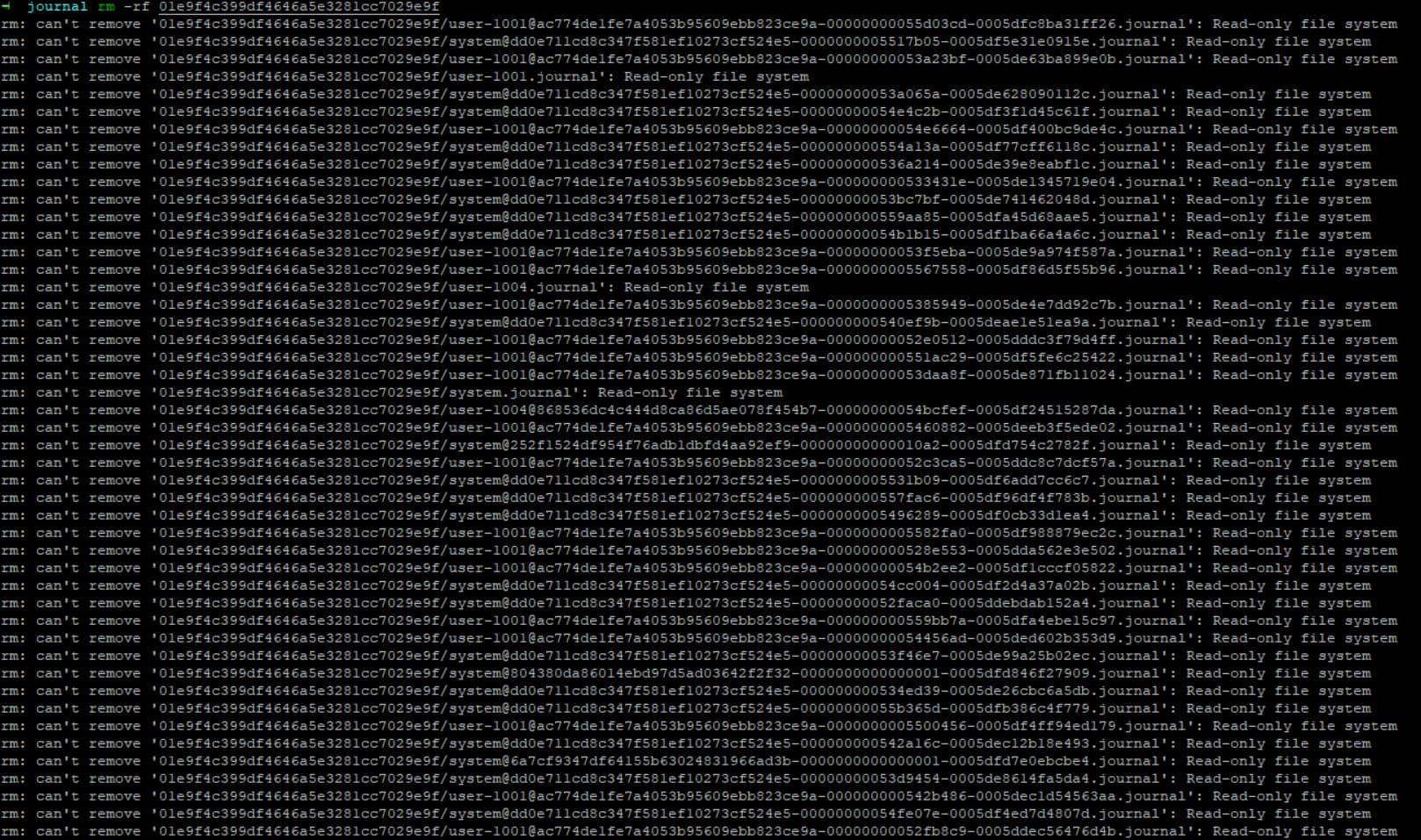
C’est normal du n’y à pas accès, le répertoire est monté en lecture seule dans le container.
ok, bonne idée, ça ne n’ai pas fait.
Je vais tout désactiver sous l’essentiel et voir si ça a un effet et si c’est le cas, je remettrais en fonction petit à petit.
Le read only est normal… L’accès se fait par l’addon SSH, donc pas root sur le FS du core, c’est juste un montage de volumes entre les 2 containers.
Concernant la base, on peut débattre sur l’utilité de garde autant d’historique (180j => 6 mois et pas un an) quand il y a les valeurs du dashboard energy pour faire ça un peu plus finement mais il y a quand même de l’optimisation à faire : Autant on peut vouloir garder les valeurs ‹ energie › et pê les valeurs de luminance (dans le cas de PV ?!? ) mais les count pour le wifi et le MQTT et ça me semble moins utile.
Il faut vérifier le journal complet des logs HA (et pas se focaliser sur un loglevel : un truc en mode debug, ça crache un peu de données)
C’est clair qu’en plus de la partie énergie et en ayant InfluxDB aussi, avoir 180 ou 365 jours à part les ennuis et les temps de chargements rallongés ça n’apporte pas grand chose
Il l’a dit, il est en loglevel critical.
Je ne vois pas ce qui dans HA peut encore cracher autant de données… c’est pour ça que je disais de voir les add-ons, comme il y en a aussi une floppée d’installé.
Oui mais on peux avoir un loglevel minimal dans configuration.yaml, tout en ayant activé séparément les addons et les intégrations, y compris en dynamique depuis l’interface.
C’est quand même là qu’on voit les limites de HAOS, c’est pénible pour chercher comme dans une VM plus classique
En l’occurence je ne sais pas trop comment on pourrait voir ça dans un autre contexte, quelle que soit l’installation.
Si le souci vient d’une intégration core ou custom, tout ce qu’on peut voir c’est le processus de HA qui consomme des ressources… mais pas plus d’infos sur ce qui se passe.
J’ai eu ça avec une intégration HACS qui déconnais, j’ai mis de temps à trouver d’où ça venait…