EDIT: le projet a complètement changé, ce premier post n’a plus rien à voir avec la méthode employée dans l’auto TPI, je laisse qd même ça pour plus tard pour ne pas perdre les infos.
Salut
J’experimente l’intégration d’une fonction de configuration automatique des paramètres TPI de versatile thermostat.
Les fortiches en math sont les bienvenus, j’avoue que je suis à la limite de ce dont je me rappelle de mes cours de l’époque. ![]()
**L’Auto TPI** (Time Proportional Integral) est une fonctionnalité intelligente qui apprend automatiquement et en continue les caractéristiques thermiques de votre pièce pour ajuster les coefficients TPI (`tpi_coef_int` et `tpi_coef_ext`) de manière optimale.
Au lieu de deviner des coefficients comme `Kp` (proportionnel) et `Ki` (intégral), le thermostat observe le comportement de votre pièce et calcule les meilleures valeurs pour vous.
Vous pouvez également utiliser ce service dans vos automatisations pour activer ou désactiver l’apprentissage dynamiquement.
## Principe de fonctionnement
L’Auto TPI observe le comportement de votre pièce (température intérieure, extérieure, puissance de chauffage) sur une période donnée pour construire un modèle thermique.
Il utilise un algorithme d’apprentissage basé sur la régression des moindres carrés pondérés pour identifier les paramètres physiques de la pièce.
Le moteur Auto TPI utilise des algorithmes avancés pour s’adapter en continu à votre environnement :
1. **Apprentissage intelligent** : Utilise un filtrage avancé (Savitzky-Golay) pour ignorer le bruit des capteurs et comprendre la véritable tendance de température.
2. **Réactivité Adaptative** : Ajuste automatiquement la vitesse de réaction du thermostat en fonction de l’isolation de votre pièce.
3. **Prise en compte de l’Humidité** : Si votre capteur d’humidité est disponible, l’algorithme prend en compte l’humidité.
4. **Auto-Nettoyage** : Il détecte les « mauvaises » données et les exclut de l’apprentissage.
5. **Détection de Dérive** : Si votre système de chauffage change (ex : changements saisonniers), il détecte le changement et peut mettre l’apprentissage en pause.
## Modèle Mathématique
Le modèle repose sur l’équation différentielle thermique suivante :
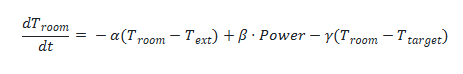
Où :
* dT_room / dt est la variation de température intérieure (dérivée).
* alpha est le coefficient de perte thermique (isolation).
* beta est l’efficacité du chauffage (puissance/volume).
* gamma est un terme de correction lié à l’inertie et à la boucle de contrôle.
* Power est la puissance de chauffage appliquée (0-100%).
### Algorithme de calcul
1. **Collecte de données** : Le système enregistre périodiquement les températures et la puissance.
2. **Filtrage** : Les données aberrantes sont écartées via une méthode IQR (Interquartile Range).
3. **Régression** : Une régression linéaire (moindres carrés pondérés) est effectuée pour trouver les valeurs optimales de alpha, beta et gamma qui minimisent l’erreur entre le modèle et la réalité. Les données récentes ont plus de poids (oubli progressif des anciennes données avec une demi-vie de 7 jours).
4. **Validation** : La qualité du modèle est évaluée via le coefficient de détermination R^2. Si R^2 < 0.3, le modèle est jugé insuffisant.
### Calcul des coefficients TPI
Une fois alpha et beta déterminés, les coefficients TPI sont calculés ainsi :
* **Coefficient Extérieur ($K_{ext}$)** :
K_ext = alpha/beta}
Il représente la puissance nécessaire (en %) pour compenser 1°C de différence avec l'extérieur.
Valeur bornée entre 0.01 et 0.20.
* **Coefficient Intérieur ($K_{int}$)** :
K_int = 1/(beta/tau_target)
Où tau_target est le temps de réponse souhaité (fixé à 30 minutes). Il représente la réactivité nécessaire pour corriger un écart de température intérieure.
Valeur bornée entre 0.01 et 1.0.
## Prérequis à l’apprentissage
Pour que l’apprentissage soit validé, il faut :
* Au moins 100 points de données.
* Au moins 10 cycles de chauffage complets détectés.
* Une qualité de modèle ($R^2$) suffisante (au moins « Fair » / > 0.3).
## Indicateurs de qualité & Suivi
L’état de l’apprentissage est visible via les attributs du thermostat :
* `learning_active` : `true` signifie qu’il collecte actuellement des données.
* `learning_quality` : Indique la confiance du système (`insufficient`, `poor`, `fair`, `good`, `excellent`).
* `confidence` : Pourcentage de confiance dans le modèle ($R^2 \times 100$).
* `time_constant` : Constante de temps thermique de la pièce (inertie).
### Interpréter les Attributs
* **Qualité** :
Insufficient: Pas encore assez de données. Continuez à utiliser le thermostat normalement.
Poor/Fair: Le modèle a quelques données mais les prédictions ne sont pas parfaites. Cela s'améliorera avec le temps.
Good/Excellent: Le système a une très bonne compréhension de votre pièce.
* **Constante de Temps ($\tau$)** :
Faible (< 2h) : Votre pièce chauffe et refroidit vite (faible inertie). Le thermostat sera plus agressif.
Élevée (> 10h) : Votre pièce a une forte masse thermique (ex : plancher chauffant, murs épais). Le thermostat sera plus lent et plus doux.
* **Confiance (R²)** : Un pourcentage montrant à quel point le modèle mathématique colle à la réalité. > 70% est excellent.
## Dépannage
* **L’apprentissage reste bloqué sur « Insufficient »** : Assurez-vous que vos capteurs de température sont fiables et mis à jour fréquemment. De grands trous dans les données peuvent ralentir l’apprentissage.
* **Le chauffage est erratique** : Si l’avertissement « Concept Drift » apparaît dans les logs, cela signifie que le comportement thermique a changé radicalement. Le système met généralement l’apprentissage en pause par sécurité. Vous pouvez envisager de réinitialiser l’apprentissage si vous avez fait des changements majeurs dans la pièce (ex : nouvelles fenêtres).
## Philosophie de l’algorithme (FAQ)
**Pourquoi ne pas utiliser les coefficients actuels pour calculer les nouveaux ?**
L’algorithme utilise une approche d’**Identification de Modèle Physique** et non une approche itérative (type « essai-erreur » ou « descente de gradient »).
1. **Indépendance de la Physique** : Les caractéristiques thermiques de votre pièce (isolation $\alpha$, puissance $\beta$) sont des constantes physiques. Elles ne dépendent pas des réglages du thermostat. Que votre thermostat soit mal réglé (oscillations) ou bien réglé, la relation physique `Puissance → Variation de Température` reste la même.
2. **Rapidité de convergence** : En identifiant directement la physique de la pièce, on peut calculer mathématiquement les coefficients « idéaux » en une seule fois (dès qu’on a assez de données). Une approche itérative qui essaierait d’ajuster petit à petit les coefficients prendrait des semaines (car chaque cycle de chauffage est lent) pour converger.
3. **Rôle des anciens coefficients** : Les anciens coefficients ont quand même un impact : ils déterminent la `Puissance` appliquée pendant l’apprentissage. Si les anciens coefficients sont « mauvais », ils vont provoquer des variations de température (oscillations). Paradoxalement, ces variations aident l’algorithme car elles « excitent » le système et permettent de mieux identifier ses réactions. Un système parfaitement stable est parfois plus difficile à identifier (moins de données dynamiques).
L’algorithme ne cherche donc pas à « corriger » les anciens coefficients, mais à « comprendre » la pièce pour proposer directement les bons réglages.
J’ai déjà commencé à intégrer ça et c ‘est en test depuis hier.
Je n’en suis encore qu’à la phase d’accumulation de donnée, donc pour l’instant aucune idée si cela va fonctionner correctement ^^
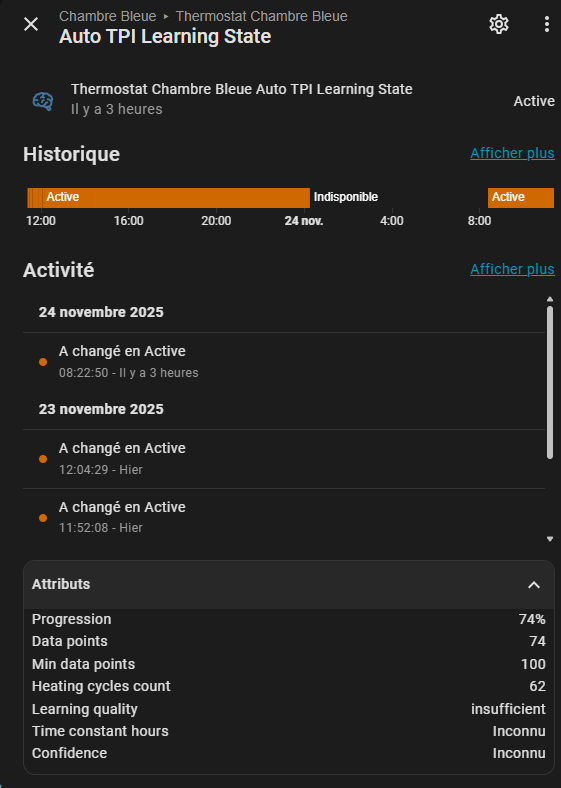
Maintenant tout ça est très théorique, et j’aurais souhaité connaitre vos avis concernant l’approche.
