Regard totalement de candide : c’est toufu mais ça m’a semblé comprehensible.
Bravo les gars, vous êtes de grands malades, je regrette de ne pas avoir de modules fil pilote…
Regard totalement de candide : c’est toufu mais ça m’a semblé comprehensible.
Bravo les gars, vous êtes de grands malades, je regrette de ne pas avoir de modules fil pilote…
sur l’EMA adaptatif et les presets de paramètres
Sur le principe, la loi c’est exactement ce qu’on utilise en identification adaptative “raisonnable” :
au début, on a un gros pas d’apprentissage du coup, on converge vite, puis le pas décroît grosso modo en 1/n, ce qui permet de ne plus courir après le bruit en gardant une petite capacité d’adaptation sur le long terme.
C’est aligné avec la logique d’un système thermique où la dynamique est lente (tau de plusieurs dizaines de minutes / heures), mais il y a quand même des dérives lentes (saisons, isolation, habitudes d’occupation…).
Sur la table de recommandations :
Apprentissage initial (alpha = 0.15, decay = 0.08)
Cela donne un système très réactif sur les 10–20 premiers cycles puis qui se “pose” progressivement.
C’est pertinent pour un démarrage “à froid” où le modèle est quasi vierge.
Apprentissage fin (alpha = 0.08, decay = 0.12)
Logique aussi : on part d’un modèle déjà bon et on veut surtout stabiliser.
Alpha démarre plus bas et décroît plus vite, donc on limite les sur-corrections.
Ça correspond à une phase où on cherche à figer la loi plutôt qu’à découvrir des choses.
Apprentissage continu (alpha = 0.05, decay = 0.02)
Là on se rapproche de ce qu’on ferait en “suivi de modèle” long terme, petit alpha, décroissance lente, donc, pas de grosses variations d’un cycle à l’autre, mais adaptation lente aux changements de saison ou aux habitudes d’occupation.
En gros, tu as 3 modes
La seule remarque que je ferais, éventuellement, c’est de relier ces presets à une notion d’horizon pour que l’utilisateur comprenne ce qu’il fait.
En gros, pour un EMA, la “mémoire effective” est de l’ordre de 1 / alpha cycles.
Donc tu pourrais documenter du style :
“Avec ces paramètres, le système garde en tête principalement les 20 / 50 / 100 derniers cycles” (ordre de grandeur, pas besoin d’être ultra exact).
Ça parlerait bien à quelqu’un qui raisonne en temps de réponse.
Sur ta remarque “decay=1, alpha=1 = moyenne pondérée (Jeedom)” :
Mathématiquement, avec alpha = 1 et decay = 1 on a alpha(n) = 1 / (1 + n), ce qui revient à donner un poids équivalent à une moyenne sur tout l’historique, donc oui, on se rapproche bien d’un comportement de type “moyenne globale” (forte inertie, pas d’oubli réel).
Sur la détection de changement de régime et le boost d’alpha
Tu as un schéma d’adaptation lent (EMA à alpha décroissant) pour éviter de suivre le bruit et en parallèle, un détecteur de changement de régime qui vient dire la structure du système vient de changer, il faut réapprendre plus vite.
C’est exactement ce qu’on fait en identification adaptative avec détection de rupture (type CUSUM / tests statistiques,…).
Sur le test en lui-même, si j’ai bien compris, tu prends les 10 dernières erreurs, tu regardes s’il y a un biais significatif avec un test t.
Au vu le contexte (thermostat, signaux lents, bruit raisonnable), ça me paraît un bon compromis car c’est simple (pas de truc hardcore type CUSUM ou GLR) et robustesse minimale (on détecte un biais persistant, pas juste un pic).
Remarques :
Cas où l’écart-type est très faible
Si std_error est très petit voire nul (par exemple erreur quasi constante), tu peux te retrouver avec un dénominateur très faible dans le t-stat.
Je mettrais une petite garde :
n = 10 : fenêtre courte
Sur 10 cycles, ça reste un test assez nerveux.
Vu que tu limites ensuite l’alpha boosté à 15 %, le risque de sur-réaction est quand même contenu.
Si un jour tu vois trop de faux positifs dans tes stats, tu pourras toujours, soit passer à 15–20 cycles, soit ajouter un critère de persistance (ex. condition vraie sur 2–3 cycles d’affilée).
Sur l’algo, cela reviens à dire: “En mode continu, je roule en petite vitesse (alpha faible).
Si le modèle devient clairement biaisé, je passe provisoirement en grande vitesse pour me recaler.”
Deux petits points d’attention :
Durée du boost
Tout dépend de comment tu gères _regime_change_detected.
Si le flag reste vrai plusieurs cycles de suite, tu vas booster alpha pendant un certain temps, ce qui est plutôt souhaitable le temps de se recaler, mais il faut juste t’assurer qu’il y a bien un mécanisme de retour à la normale (reset du flag quand l’erreur se recentre).
Interaction avec les saturations
Sur un système de chauffage, tu peux avoir des phases où la commande est saturée (0 % ou 100 %), ce qui peut perturber la distribution des erreurs.
Il faut au moins vérifier que ce cas ne déclenche pas de fausses détections de “changement de régime”.
En tous cas, c’est un très bon travail. La démarche est rigoureuse et cohérente avec les principes classiques d’identification adaptative (apprentissage rapide au départ, stabilisation progressive, et mécanisme explicite de changement de régime). La logique EMA + décroissance + boost temporaire en cas de rupture est bien pensée, continue dans ce sens
Ça me fait vraiment plaisir d’entendre ça, étant autodidacte tant dans ce domaine qu’en progra.
Mes cours de stats remontent à ma fac d’eco quelques années avant toi ( je suis de 76 )
Il faut que je vérifie, mais l’algo rejette tout cycle avec un écart type trop faible pour éviter les divisions proches de zéro. Du coup ça devrait éviter ce soucis aussi.
En fait il ne fait le boost qu’une seule fois et reviens dans son statut précédent.
Je pars du principe que si il y a erreur persistante, ça reboostera encore au bout de n cycles. On n’est pas pressé non plus
Tous les cycles en saturations ( 0 et 100 sont ignorés aussi ![]() )
)
Je prend note de ta proposition sur la doc.
Merci bcp
@BBE merci d’avoir pris le temps de regarder la doc.
Edit: je pense qu’il faut peut être splitter la doc en 2 , sortir la partie explication de l’algo dans une page séparée comme a fait @Jean-Marc_Collin pour l’algo TPI.
Bon, je pense avoir terminé tout ce qui est necessaire pour pouvoir commencer un beta test. ![]()
@Jean-Marc_Collin on peut s’appeller si tu veux pour en discuter voir comment tu imagines organiser tout ça.
Edit: je te soumets un PR temporaire ( ou pas ) pour qu’on échange dessus.
Note: On arrangera ensemble le config_flow pendant les tests, j’ai bien quelques options qu’on ne va peut être pas garder suite aux résultats du test.
Bonjour à tous !!
Je tombe par hasard sur ce post et je suis ravi de lire que la dernière brique qui me manquait est en cours d’élaboration !!!
Bravo à vous tous !
Si vous avez besoin de tester en condition réelle, je suis à votre disposition.
J’ai différentes configurations :
Chauffages électriques (inertie sèche) dans chaque pièce, gérés individuellement par versatile.
Poêle à Pellet dans le salon fraichement installé, en cours d’implantation en // avec le chauffage électrique, géré par 2 versatiles individuellement.
Test en cours également de Intelligent Heating Pilot pour anticiper le démarrage de la chauffe par rapport à mes plannings.
Après 24h d’apprentissages quelque soit la méthode, on arrive déjà sur des valeurs tout à fait correctes.
(edit: graphs mis à jours: 13/12/25 10h30 )
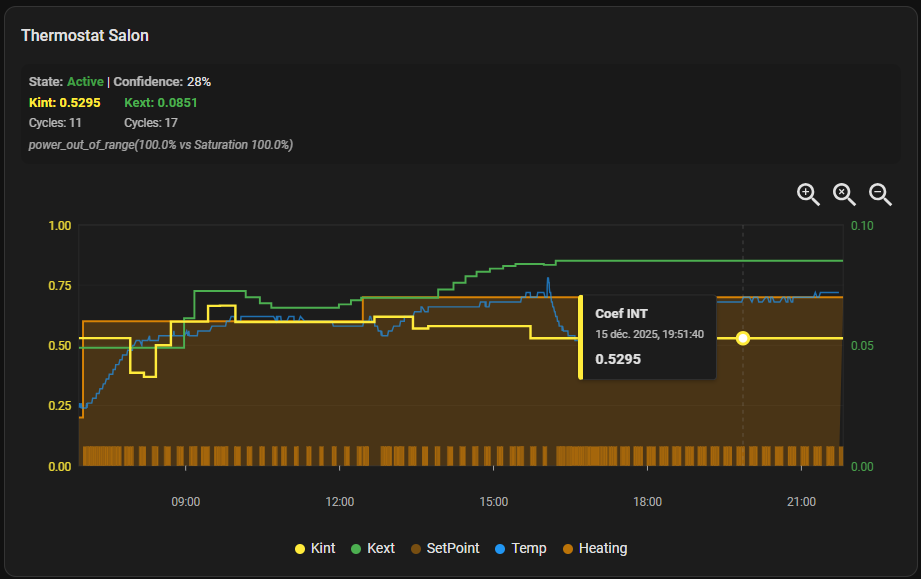
Ici c’est 100% radiateurs electriques.
Salon et cuisine sont en fait 2 thermostats dans la même pièce, le coté cuisine un peu moins bien isolé.
On voit que le mode ema arrive avec du retard avec beaucoup moins d’oscillations que le mode moyenne.
Chambre bleue, petite pièce vraiment mal isolée, lancée donc en EMA version affinage. Ce sont les coeff de départs que j’utilise habituellement. On voit bien que ca ne s’emballe pas et qu’on reste autour de cette zone de confort.
Chambre verte c’est très interessant. Le Kint chute très rapidement à une valeur minimaliste. Cette pièce est naturellement chauffée par l’étage du dessous. Les portes sont toujours ouvertes, j’ai laissé ouvert pour l’apprentissage aussi. Il ramene juste ce qu’il faut de boost en Kext pour l’isolation. C’est parfait.
SdB: radiateur seche serviette. isolation correcte. L’apprentissage n’a démarré que vers 6h. Ca c’est calé très vite.
Après 10 cycles validés pour Kint, on est déjà bien dans les clous en général. Il en faut 50 pour que l’apprentissage s’arrète.
Comparé à ce que j’ai pu experimenter avec l’algo Jeedom, c’est beaucoup plus doux et rapide.
Je pense que ce qui fait la différence, c’est que l’algo Jeedom ajuste par rapport au delta T° ambiante vs Consigne.
J’ai changé ça par T° ambiante, capacité du radiateur et de son état de chauffe ( l’inertie fait la diff à mort )
Ca part pas vers la lune dans les premiers cycles.
Ca devrait pas trop mettre le foutoir pour les fêtes.
Excellent tout ça. C’est un boulot de dingue que vous avez fait avec des bases théoriques solides. Je suis impressionné et y a longtemps que je ne l’avais pas été à ce point là.
Je finis ma v8.3 ce week-end, j’ai vu ta PR, je vais me l’installer et jouer avec. Au besoin on se monte un zoom en effet pour fignoler notamment le config-flow. Il faut que je me rende compte en réel.
On est sur les rails pour une beta pour Noël (un peu juste peut être) ou une fin d’année, ce qui serait une belle perf. ![]()
![]()
Fait un backup avant, vu que j’ai perdu mon historique début décembre. Je ne sais pas si c’est à cause de mes changements.
Mais bon depuis j’ai prévu la migration.
Juste B R A V O !!! Vous êtes impressionnants
Moi même ancien utilisateur de Jeedom cette fonction va combler un vide dans home assistant
++
je viens d’actualiser les graphs au dessus.
L’apprentissage de Kint ne se fait que pendant les cycles de chauffe pour atteindre la consigne.
En approche de la consigne( et en overshoot ) , c’est le reglage de Kext qui se fait.
Dans la config je conseille de laisser cocher par défaut: “Conserver l’apprentissage externe jusqu’à la fin de l’apprentissage interne”
Sinon la regle c’est 50 cycles par coeff.
Il y a beaucoup plus de cycles pour Kext que pour Kint, c’est bien qu’il continue de s’ajuster tant que l’autre a pas terminé.
Je pense qu’on sautera cette option pour l’imposer après les premiers résultats des tests.
Une recommendation pour un bon apprentissage rapide, c’est d’avoir des phases de chauffe pas à 100% ( car on n’apprend rien en saturation ) pour forcer Kint à s’ajuster sur les premiers cycles ( qui ont le poid le plus important ).
Ouvrir un peu les fenêtre pour faire descendre rapidement de 1-1.5° max ( ce qu’il faut pour rester en dessous des 100%, sinon baisser la consigne ) et le laisser remonter. Et recommencer.
Laisser qd meme tourner un peu autour de la consigne pour que Kext bosse un peu aussi.
Ca accelerera l’apprentissage au départ.
Après ca marche très bien aussi en gardant ses habitudes, c’est juste un peu plus long.
Hello @KipK
Est ce que je peux me lancer dans la phase de test ?
Si oui quelle est la branche concernée ? As tu une mini doc pour le déploiement ? Par exemple
Je ne suis pas rompu à ce genre d opération sur HA.
non on termine le PR avec @Jean-Marc_Collin on vous dira tout çà.
D’autant que j’ai refactorisé pleins de choses hier et pas encore testé ![]()
Edit: @Jean-Marc_Collin c’était un gros refactor. T’as du te prendre un paquet de notifs GitHub avec tous mes commentaires.
J’en ai un peu chié à réparer les tests…
J’ai vu que t’y avais passé ton week-end alors que j’étais absent.
Faut pas hésiter à me « déléguer » la mise à jour des tests, comme je te disais, c’est un peu touchy dans le cas des gros refacto. Ce qui est important c’est de ne pas dévoyer le test pour qu’on s’assure de la non reg.
@Bensmens ça avance bien mais encore un peu de patience. Livrer trop tôt est toujours une mauvaise idée pour tout le monde. Et je vais d’abord le faire tourner 2 ou 3 jours chez moi comme toujours avant de publier. Quand ça merde c’est madame qui n’est pas contente mais ca évite des dizaines d’autres madames pas contente car le chauffage marche plus ![]()
Vous êtes très forts, bravo à vous, je lis de loin mais avec intérêt.
Bob
J’ai pris une grosse charge Vendredi soir. Ca m’a collé à la maison pour le week end ![]()
On va avoir une petite carte lovelace pour le beta test:
Histoire que tout le monde ai les memes graphiques. Je fignole 2-3 trucs.
Bonjour.
Cet ajout semble merveilleux. Merci pour votre travail.
Il me vient une petite question qui concerne ma propre installation.
J’ai une pac air/eau et un insert a granules.
Je le gère de cette facon:
Dès que la température ext est <7°c je mets en route l’insert et baisse le radiateur de la pièce dans laquelle se trouve l’insert, je gère ensuite en tout ou rien l’insert suivant hysteris.
Dans le cas où l’insert s’allume, la chaleur finie par se propager aux autres pièces, VT fait donc le job et coupe ou diminue la puissance des radiateurs.
Mon interrogation est donc dans la suivante:
Comment va se comporter l’auto Tpi dans ce cas, est-ce que cela va venir perturber les calculs et du coup je perdrais l’intérêt de l’auto Tpi? Ou, il ne prendrait en compte cette plage pour ses calculs ?
@Ced.cou Ca va faire chuter les coeff calculés quand l’insert tourne
C’est pas forcément une mauvaise chose mais ca posera soucis quand il n’y a que les radiateurs qui tournent
Le mieux serait de faire un apprentissage complet sans insert, et de noter ces coeffs.
Puis refaire un apprentissage avec insert.
Tu auras 2 jeux de coeff que tu peux envoyer dynamiquement a ton vtherm avec le service call Set TPI parameters depuis une automation quand l’insert s’allume ou quand il est etteint.
Par contre un apprentissage prend plusieurs jours selon le nombre de cycle de chauffe complets. Kint n’apprend que quand on a des differences notable entre la consigne et la temp ambiante ( temp < consigne ) et que la puissance n’est pas saturée ( 100% ou 0% ). Il elimine aussi le premier cycle de chauffe. Et quelques autres conditions détaillées dans la doc.
Après 2 jours j’en suis à 16 cycles Kint validés ici, sur 50. Mais j’ai très peu de changements de consigne aussi et l’inertie est lente.
Tu peux aussi mettre en pause l’apprentissage depuis un service, donc tu peux automatiser ca aussi. Qd l’insert s’allume, stopper l’apprentissage. Quand il est éteint, ( et après x minutes le temps que la pièce soit stabilisée ) , relance l’apprentissage ( sans reinitialiser )
Quand on est autour de la consigne, seul Kext apprend.
Après si tes radieurs ne chauffent pas pendant qu’insert est allumé, dans tous les cas ca n’apprendra rien, donc pas besoin d’automatiser ça. Quoi que ca peut continuer de faire bouger Kext et fausser les résultats ( il va trouver que l’isolation est vachement bonne… )
Est ce qu’une fenêtre ouverte suspend l’apprentissage ? si oui, au moins pour la pièce principale, est ce qu’on ne pourrait pas faire un capteur d’ouverture qui s’ouvre ou se ferme en fonction de la température de l’insert (comme proxy de son fonctionnement) ?
Merci de ta réponse.
Je perds un peu l’intérêt de l’auto tpi dans ce cas, si j’ai bien compris ils seront dynamiques en fonction de différents critères.
L’idéal serait 2 réglages dynamique de pid peut être?