Désolé pour pour l’expression GA, qui veut dire « Groupe Adresse » en KNX.
Pour cette partie KNX, je suis plutôt à l’aise même si je suis autodidacte.
Je vais essayer de vous expliquer mon cheminement:
Très assidu sur le forum KNX français ( www.knx-fr.com à recommander pour les pratiquants de HA associé à KNX), les évolutions des uns et des autres, nous ont amenés à choisir les VMs et les CTs sous proxmox, pour sécuriser notre domotique.
Tout d’abord, nous faisons le choix d’utiliser toute la stabilité et le fiabilité du KNX, en lui déléguant le maximum de choses, dont les automates, et les régulations.
Nous faisons donc le choix de ne dépendre qu’au minimum d’une connexion internet.
Et pour nous HA, est là pour servir d’interface graphique soit pour tablette au domicile, soit smartphone à distance.
Pour beaucoup nous venons de Lifedomus qui nous donnait toute satisfaction, Deltadore ayant abandonné la maintenance de ce superviseur (avec une superbe ergonomie par ailleurs), et cette douche nous a pour la plus part amené à HA, avec son superbe dynamisme et sa philosophie totalement Open Source.
D’ailleurs, après avoir investi beaucoup de temps sur SNIPS avant son rachat et son abandon par SONOS, nous sommes ravis de l’intégration de Rhasppy dans l’équipe de HA. ( une dépendance vis à vis de Google Home ou d’Alexa est une facilité, mais me parait bien dangereuse).
Pour revenir au choix des VMs et les CTs sous proxmox, nous trouvons que le travail à réaliser pour une supervision de bonne qualité avec HA, demande vraiment un grand investissement en temps, et mérite de se pencher sur la sécurité matériel du support.
Avec un VM pour HA, on sauvegarde la VM, sur le NUC qui fait tourner HA, on externalise un backUp sur le réseau, plus un autre backup déconnecté du réseau.
En phase de développement, on peut cloner autant de VM d’HA que l’on veut, faire des tests puis faire le choix de la meilleure option.
Si le NUC est mort, on réinstalle Proxmox sur une autre machine, on y réinstalle la dernière sauvegarde, et tout est reparti.
Pour la partie développement de la configuration de HA, j’utilise Studio Code Serveur, avec un Git vers mon Github perso, ce qui permet de faire du versionning. Ce qui fait sauvegarde du code et test de versions.
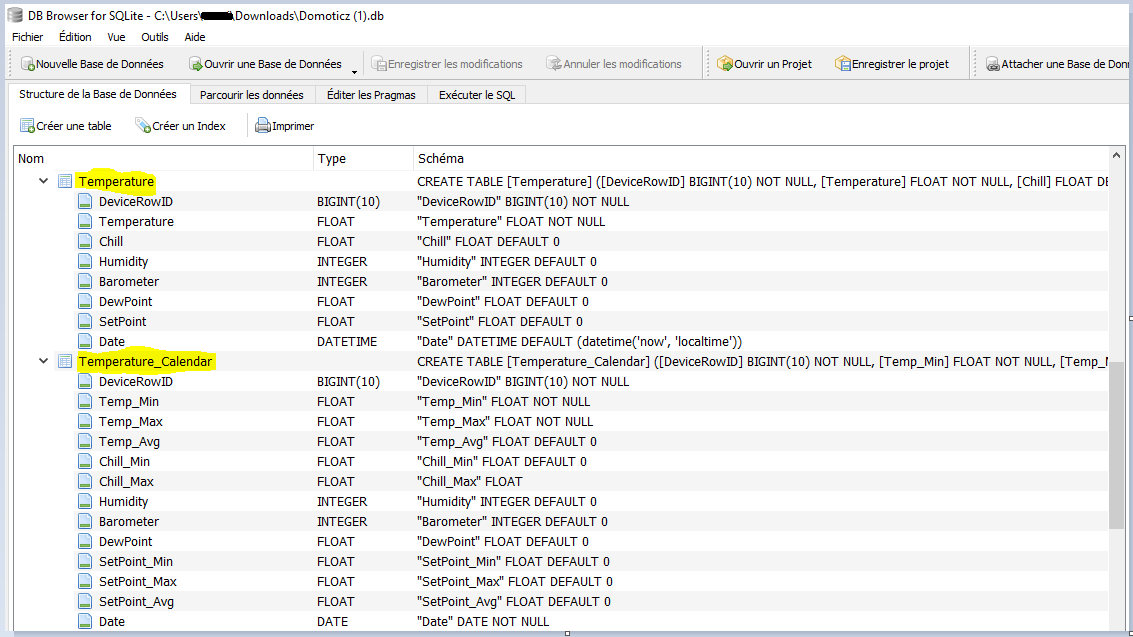
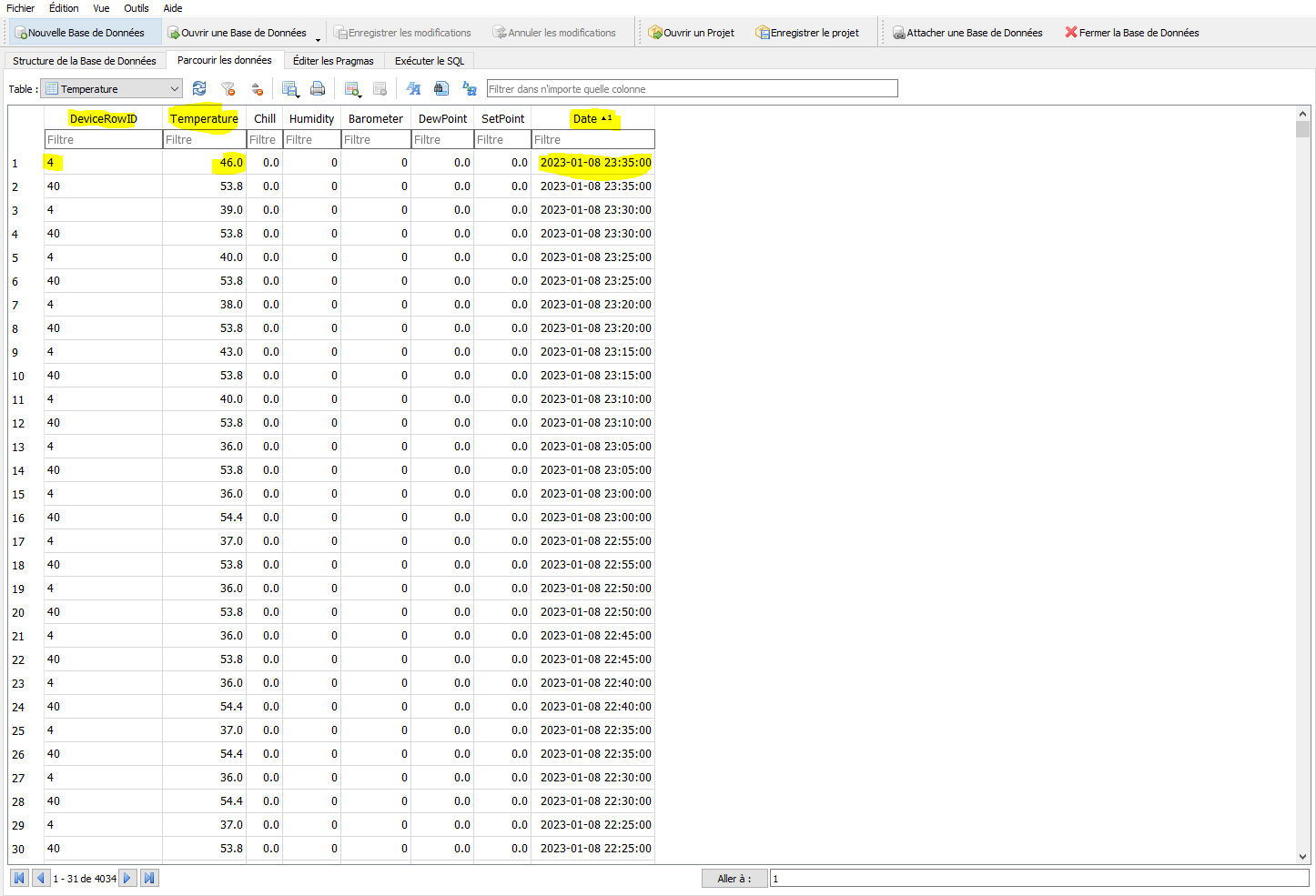
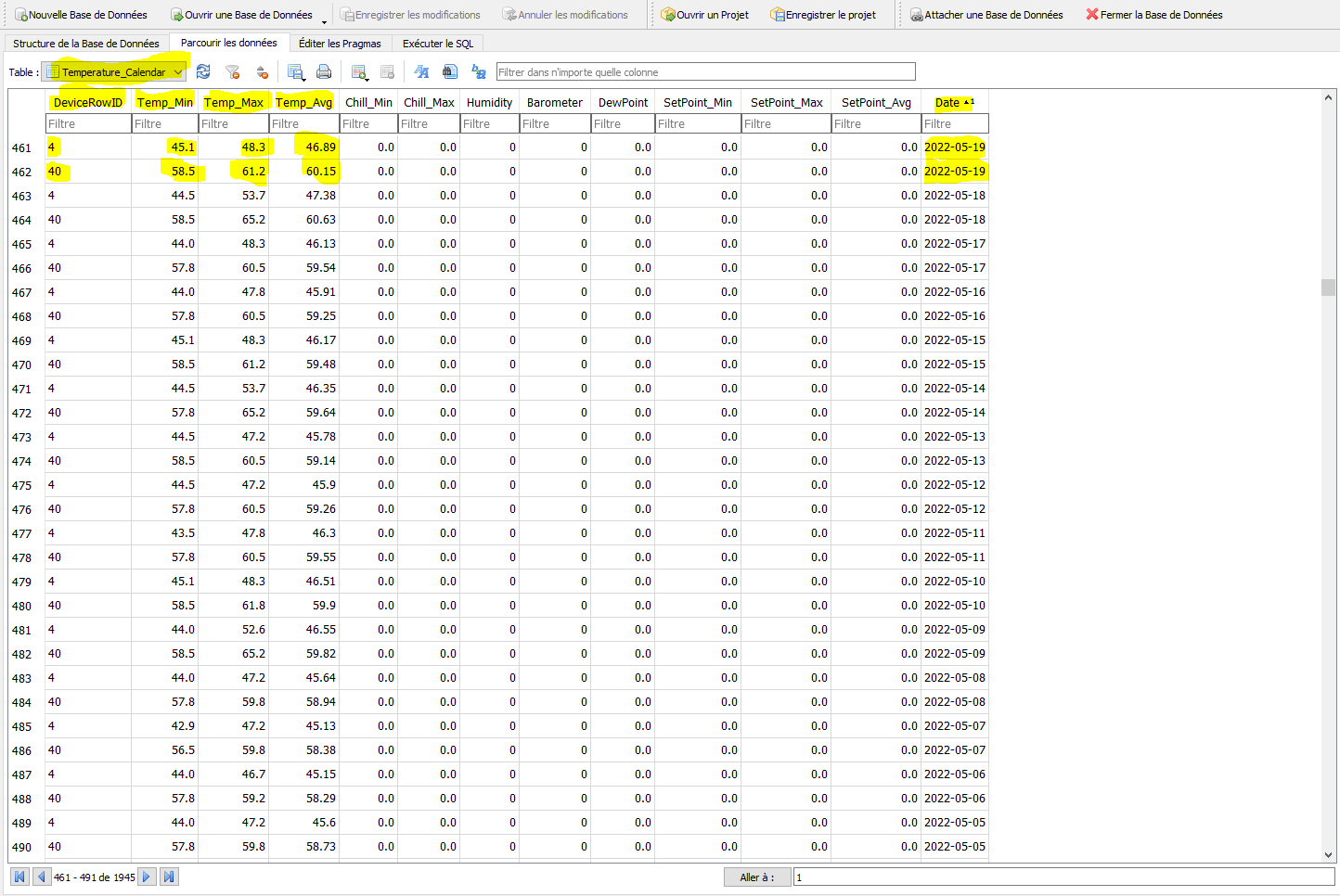
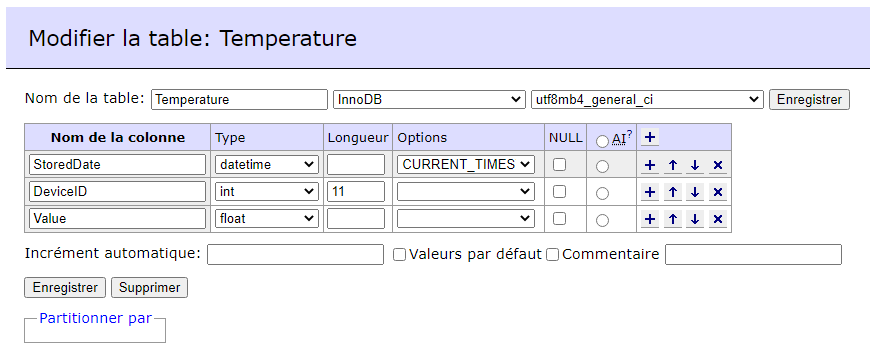
mais le sujet de ce post est : « Externaliser son historique - Stockage long terme » et donc là je suis peut être hors-sujet.
Actuellement j’ai bien relié Node RED sur un CT, avec Ha, mais pour influxDB le CT est fonctionnel, mais je bloque pour le relié à HA. Je n’ai pas compris quel différence il y a avec l’addons influxDB pour HA???