De retour…
Mes branchements on l’air OK (le système m’entend…même si il ne me comprend pas)
Par contre pas de retour sur le HP et on dirait que le service s’arrête après le 1er essai.
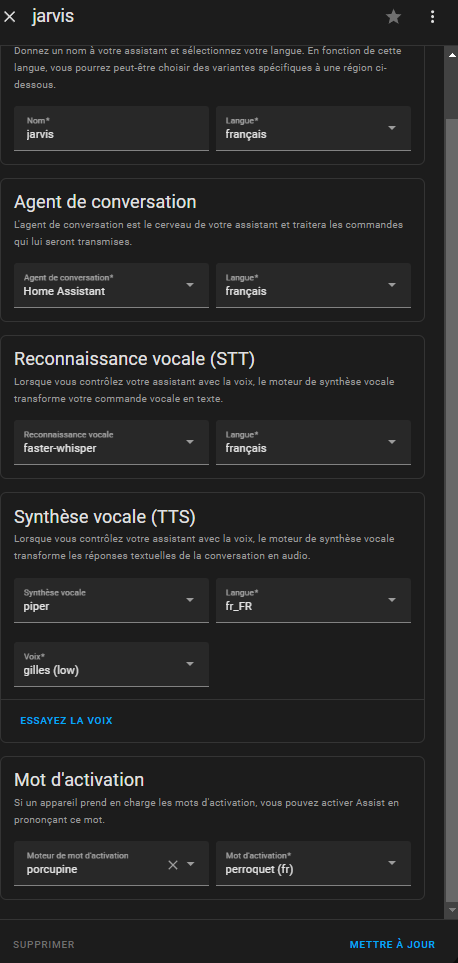
Voici ma config pour Assist:
est-ce que tu penses qu’il y aurait une solution pour remédier à cela ?
Je pense par exemple au projet jarvis sur rpi, la reconnaissance vocale était entrainée par les utilisateurs avant de télécharger la voix de jarvis
Je saurais te dire, je me suis pas pencher sur une solution. Pour moi c’est pas stable , prêt , a être utiliser. Patienter, qui est des améliorations, mais pour un RPI4 chez pas si c’est une bonne voie a prendre.
Alors après plusieurs tests, j’ai réussis à avoir quelque chose de stable en gardant la langue française.
Dans la configuration de whisper j’ai réglé comme modèle « small-int8 » et dans Beam size j’ai mis la valeur à « 5 ».
Résultat, la compréhension de l’assistant est vachement meilleur même s’il a encore un peu de mal avec le mot « éteint »
Bonsoir à tous ! Merci pour cet echznge hper intéressant.
Après avoir suivi le tuto vidéo, j’en arrive au point où le satellite réagit 1 pois puis semble ne plus reagir. Comment avez vous réglé le problème ?
Pour info, je n’ai pas séparé les deux i2s dans mon code.
Chapeau, j’avais pas vu les options de configuration de whisper et j’avais langue sur en
J’ai mis en FR et small-int8. j’ai pas modif en 5 Beam Size, j’ai laisser sur 1.
Au premier essai, ca a fonctionner
[03:24:05][D][voice_assistant:422]: State changed from STOPPING_MICROPHONE to AWAITING_RESPONSE
[03:24:24][D][voice_assistant:529]: Event Type: 4
[03:24:24][D][voice_assistant:557]: Speech recognised as: " Allume escalier"
[03:24:24][D][voice_assistant:529]: Event Type: 5
[03:24:24][D][voice_assistant:562]: Intent started
[03:24:25][D][voice_assistant:529]: Event Type: 6
[03:24:25][D][voice_assistant:529]: Event Type: 7
[03:24:25][D][voice_assistant:585]: Response: "Allumé"
Moi j’avais mis en mode « en » pour faire des tests en anglais mais j’avais oublié de le repasser en français je trouvais ça bizarre que dans le debbug les mots soit en anglais
Ca fonctionne toujours mieux avec les bons paramètres
Je n’ai pas de RPI sous la main, mais j’ai enfin pris le temps de tester Vosk à la place de faster-whisper et c’est impressionnant ( comme toujours vu que c’est Mike alias Synesthesiam qui est au commande).
La rapidité de traitement sur mon i3/8Go est incomparable par rapport à faster-whisper…et même dans la langue de Molière.
Si l’un d’entre-vous tourne sur RPI et peux tester afin de me faire retour pour ma culture personnelle…
@+
ps : vosk est disponible dans les modules complémentaires
Ce n’est pas rhasspy mais vosk ( du même dev)
Dans la conf, le strict minimum ( allow unknow) fais déjà très bien le taff. 1 seconde tout au plus entre la fin de la commande vocale et l’action correspondante
Installation
Follow these steps to get the add-on installed on your system:
Navigate in your Home Assistant frontend to Settings → Add-ons → Add-on store.
Oui, tout à fait.
Soit tu remplace dans ton assistant actuel Faster-whisper par Vosk, soit tu créé un autre assistant avec Vosk pour le STT.
Une fois le module installé, tout comme pour Piper/Faster-Whisper, une intégration va être découverte pour ajouter Vosk à Wyoming.
Je suis bluffé par la rapidité, c’est aussi réactif que le STT de Nabu-Casa. A voir si cela se confirme sur RPI
Merci pour ce rapide retour.
C’est bizarre que Nabu n’ai pas mis encore en avant cette solution. Ils vont peut-^tre le faire demain lors du chapitre 5.
J’ai essayer vosk aussi sur RPI4 4Go, ca marche mieux que faster-whisper et c’est plus rapide.
En 2s ca répond, et ca mange moins de RAM et de ressource proc aussi. Ca deviens intéressant, même avec un ATOM echo
Il reste à trouver un bon réseau de microphone compatible ESP32 qui fasse le beamforming, AEC et touti-quanti pour différencier la commande des autre voix dans un environnement « pollué » pour que Google Nest , Amazon Echo et consorts finissent au fond du placard.